Fitting CAR and SAR Models
Lecture 20
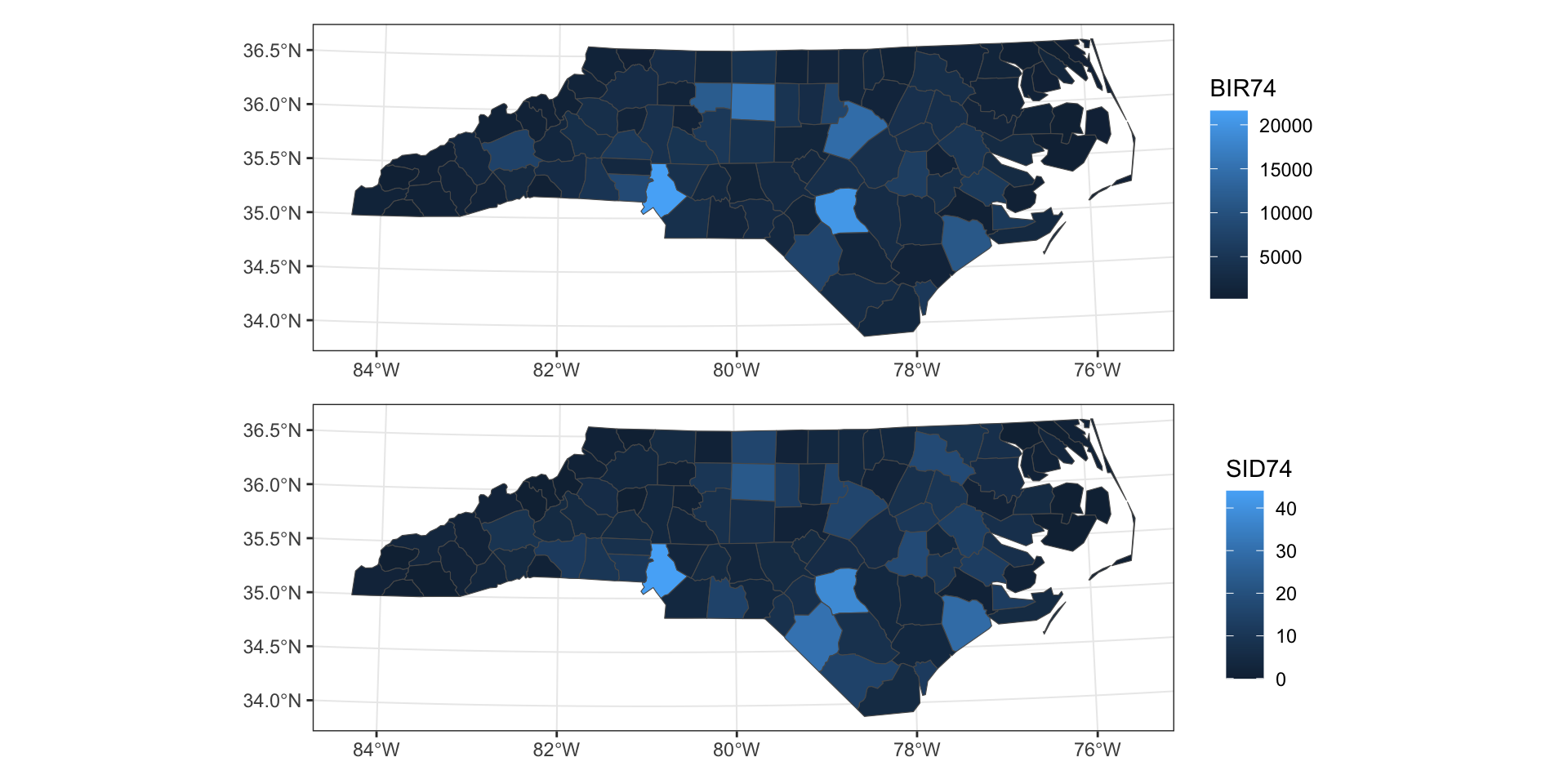
Example - NC SIDS
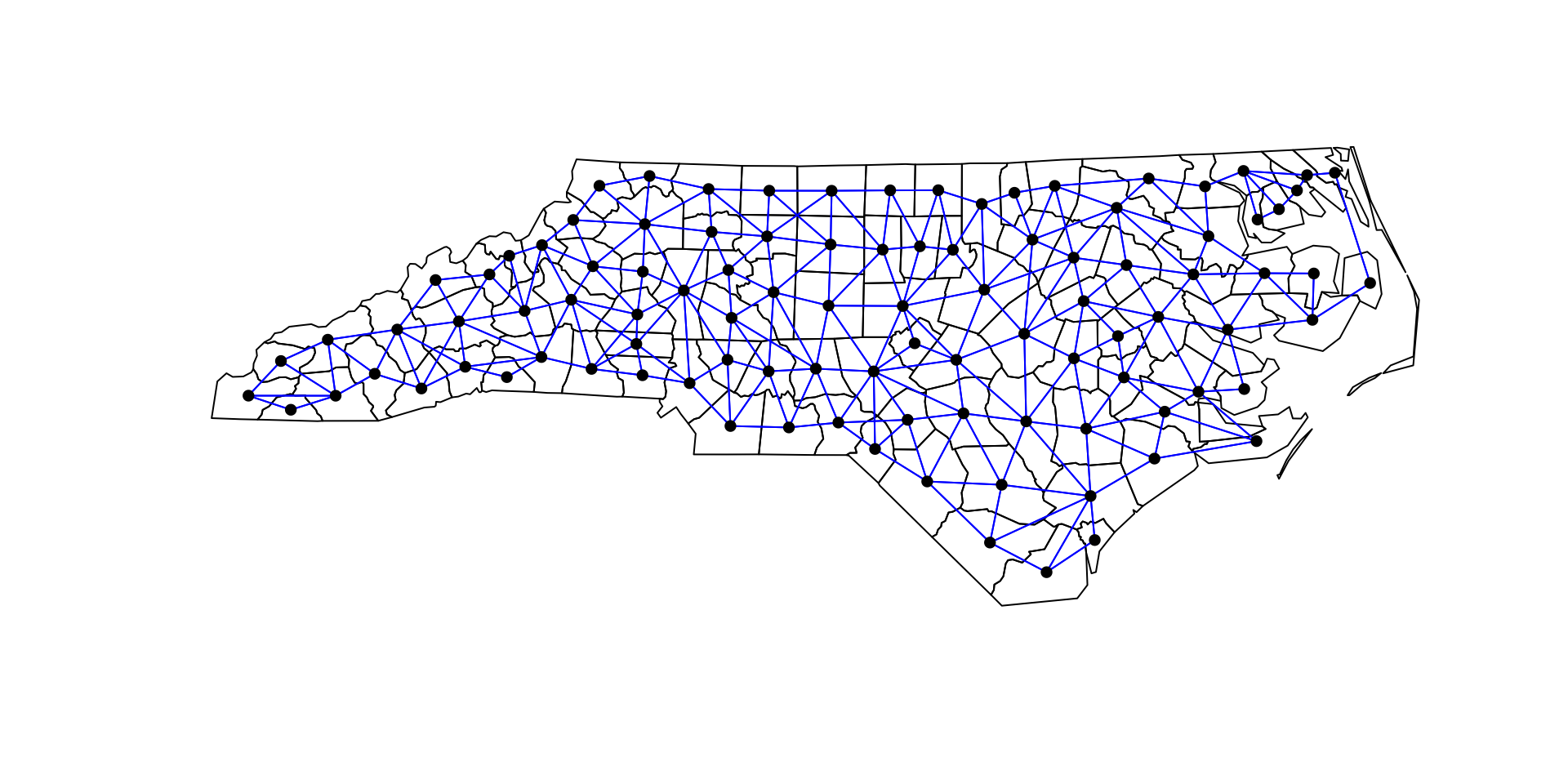
Plotting listw
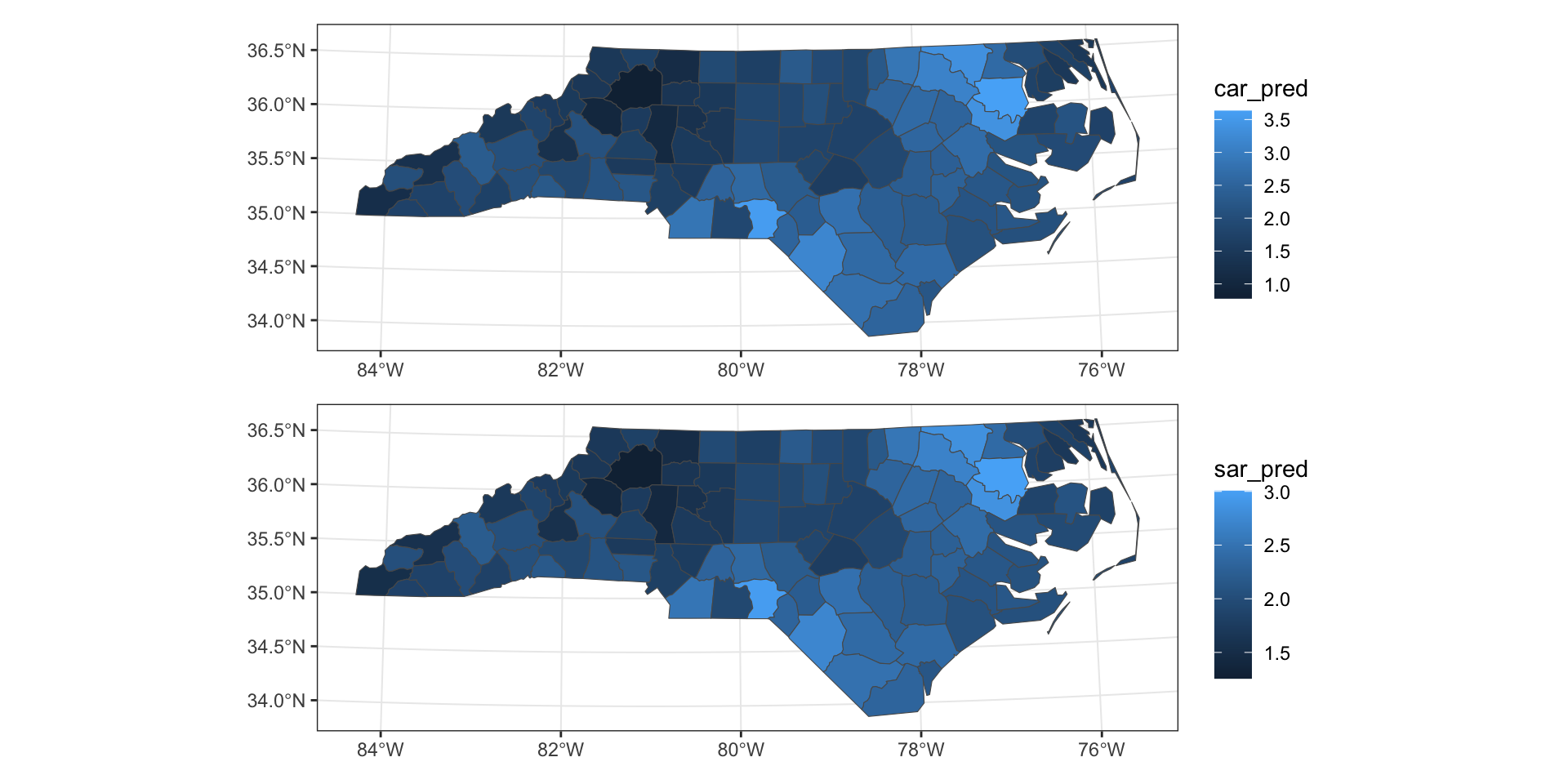
Predictions
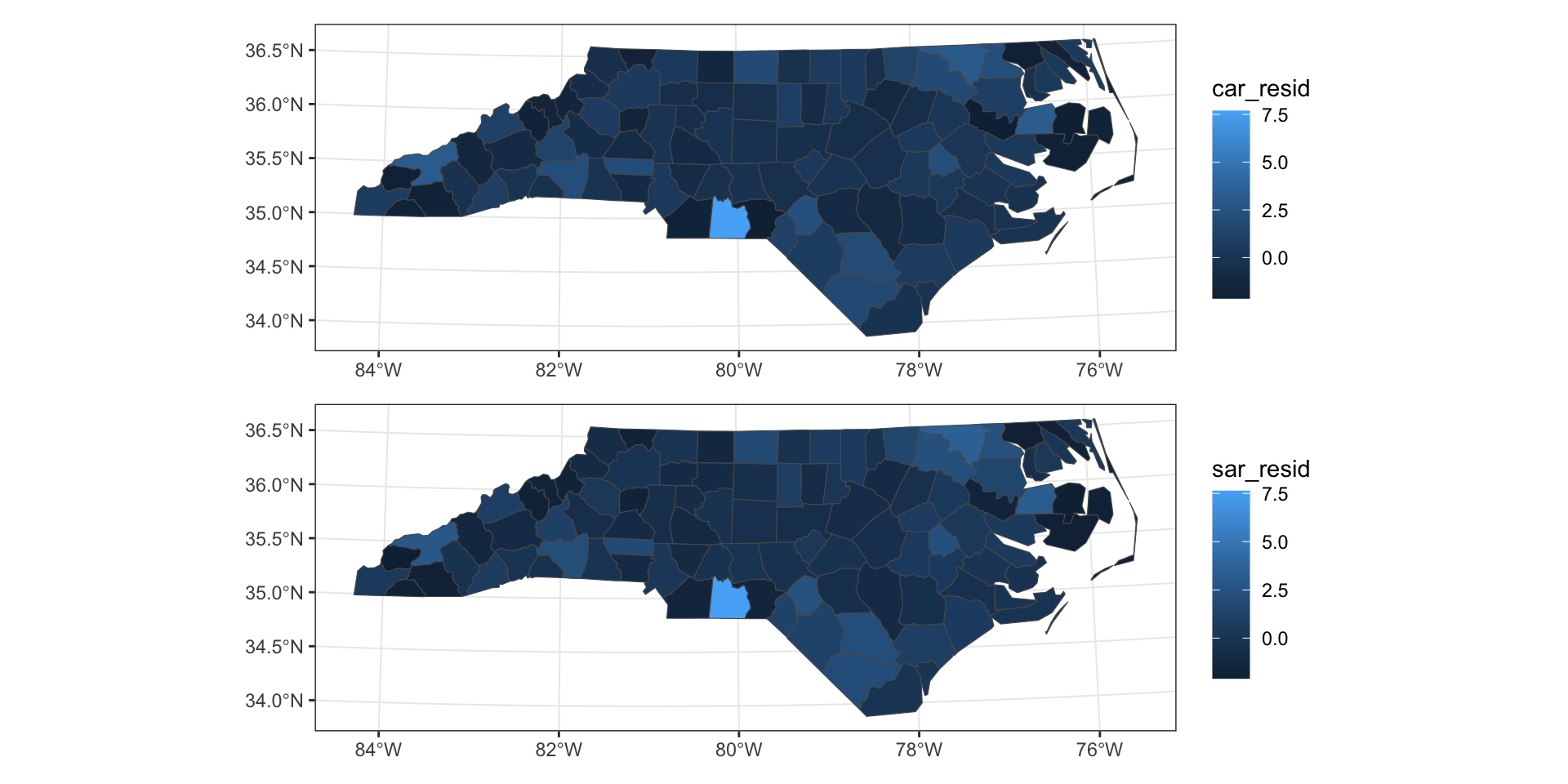
Residuals
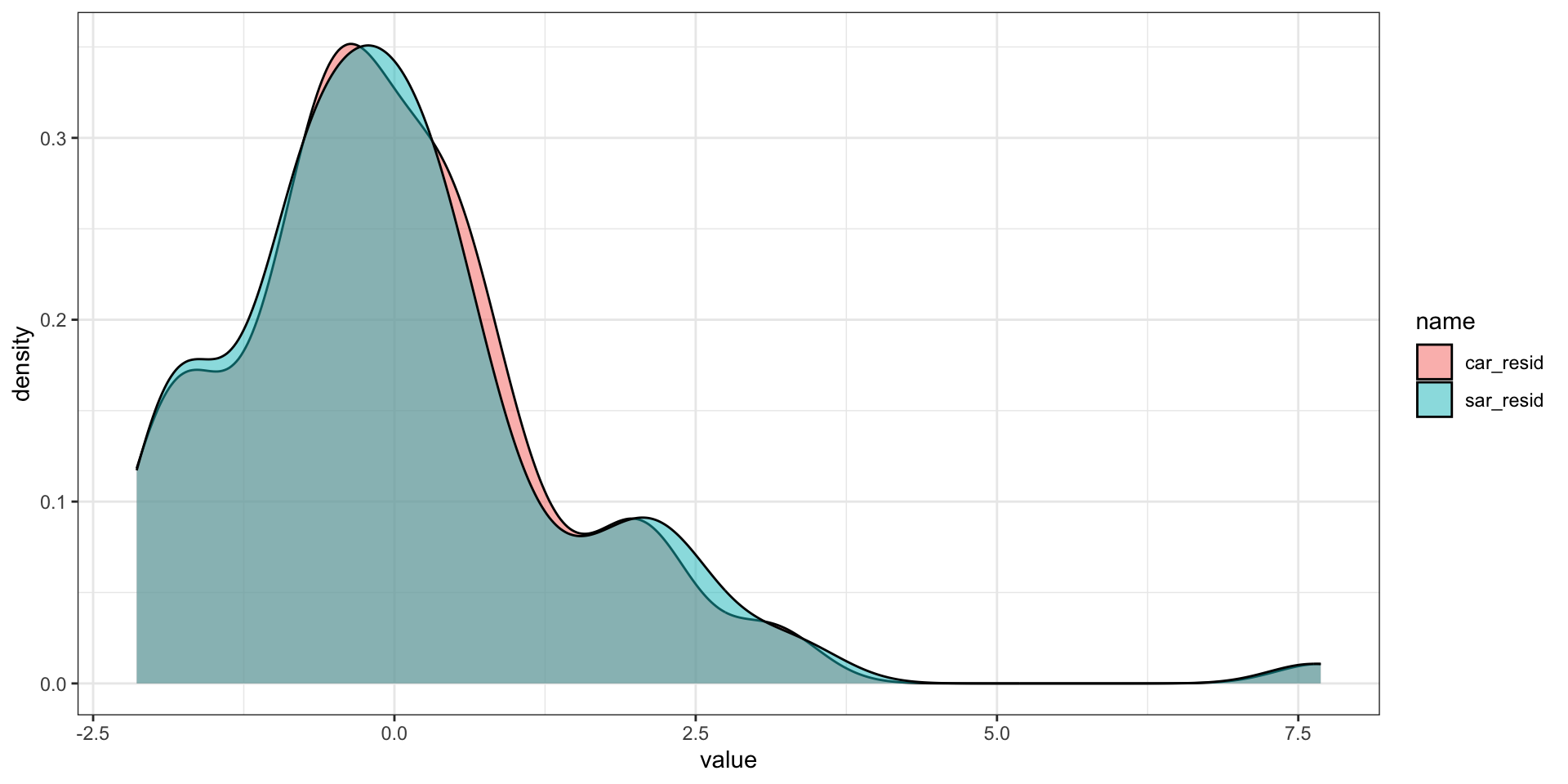
Residual distributions
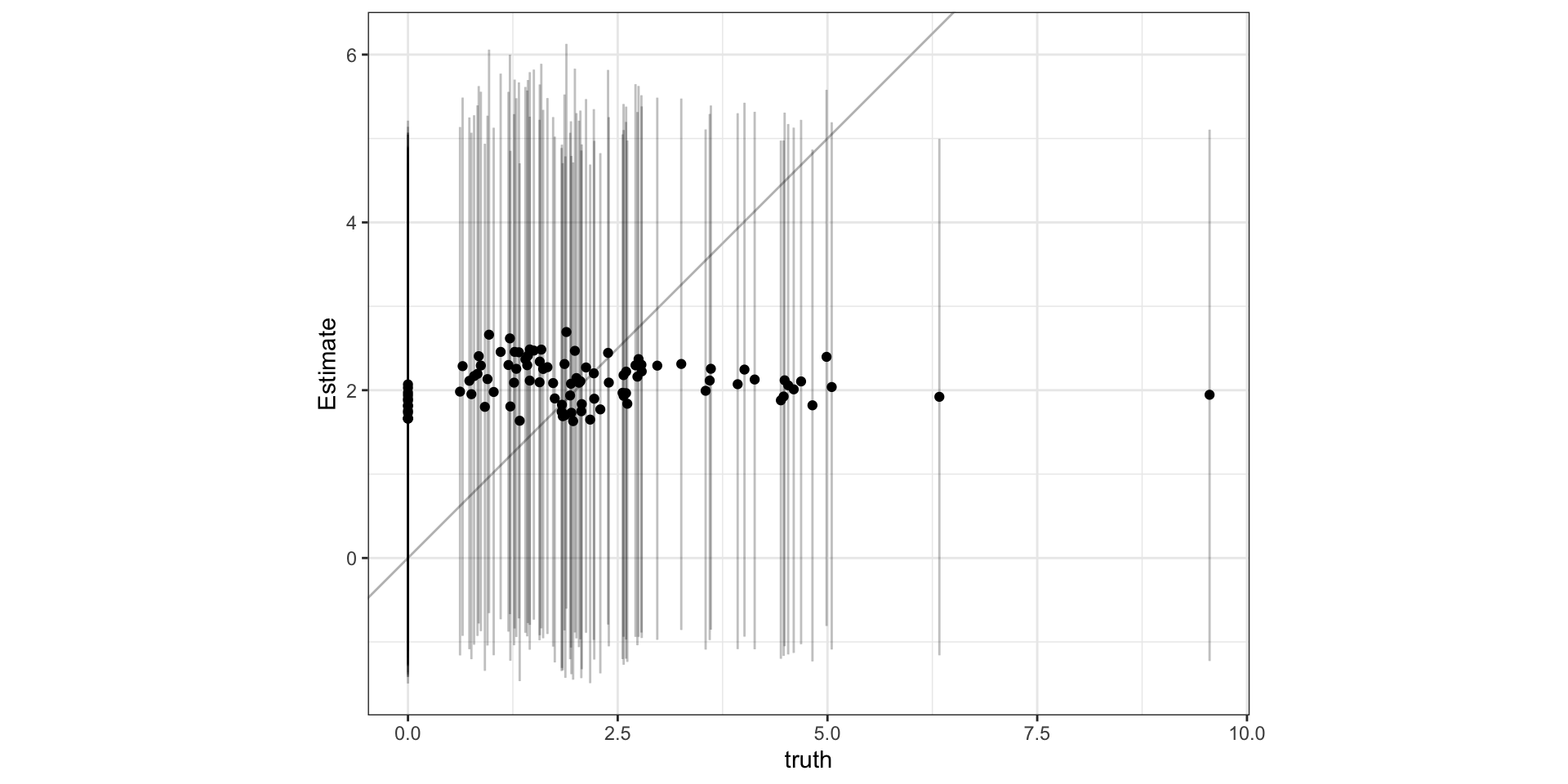
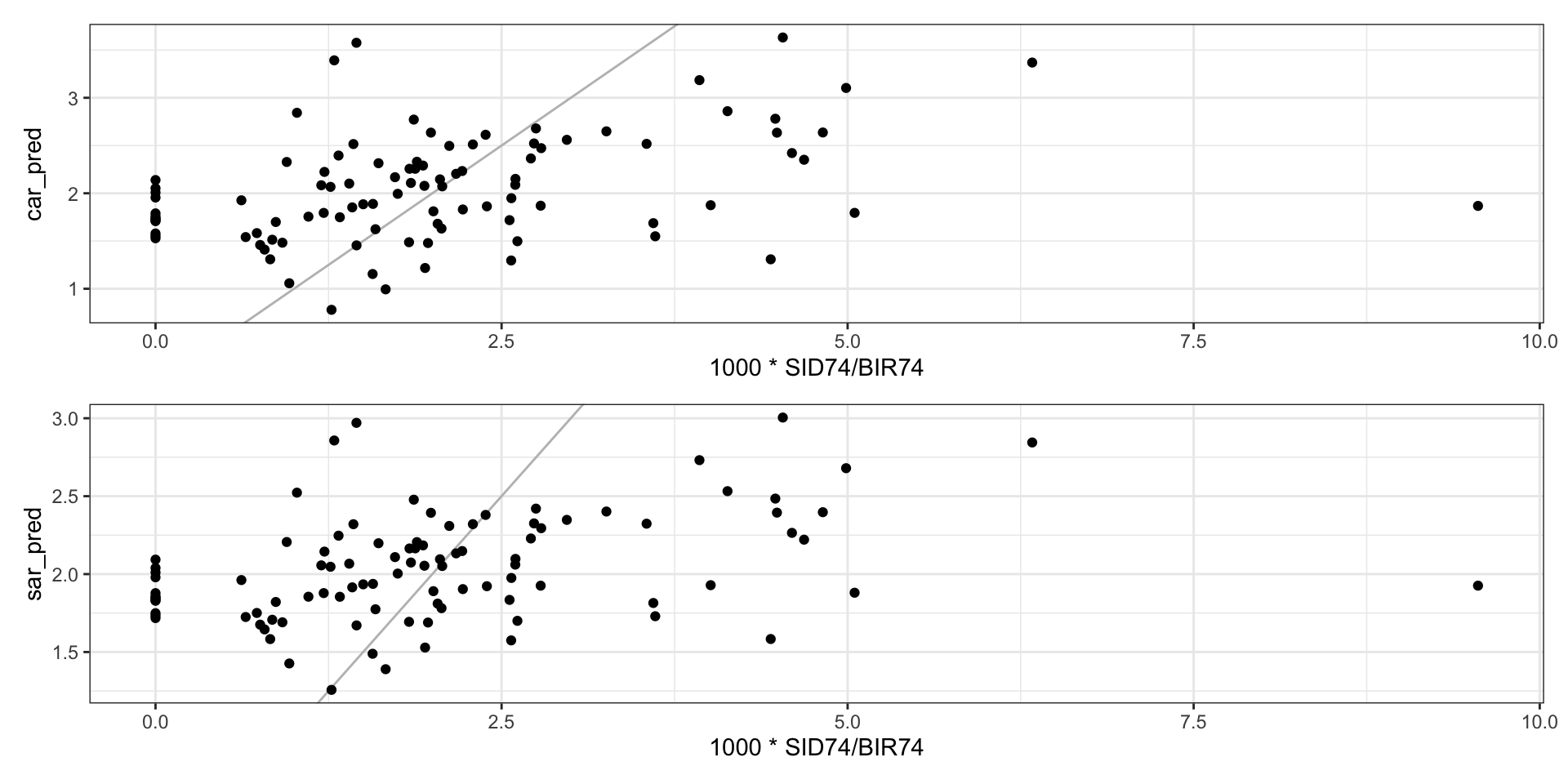
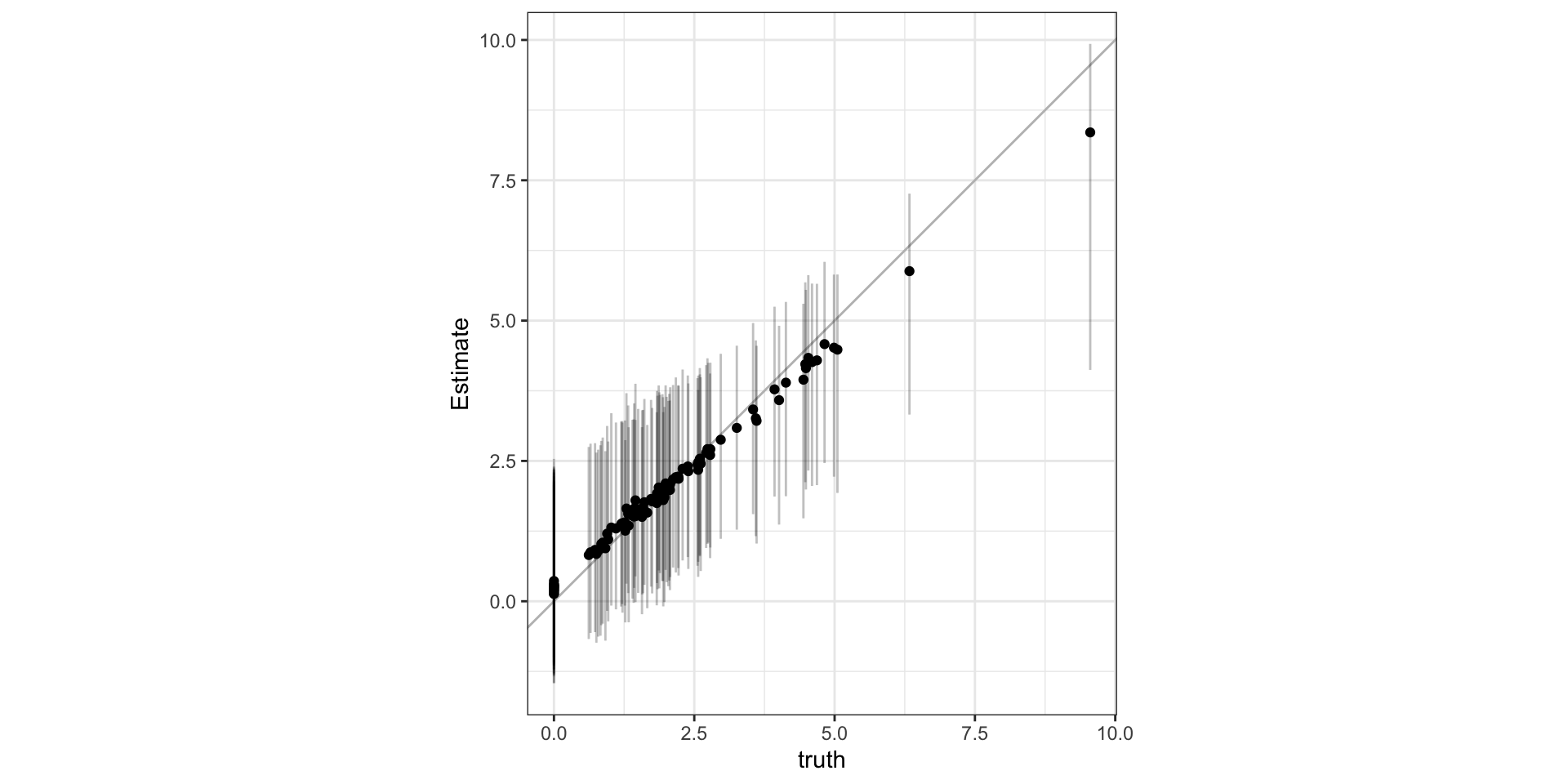
Predicted vs Observed
What’s wrong?
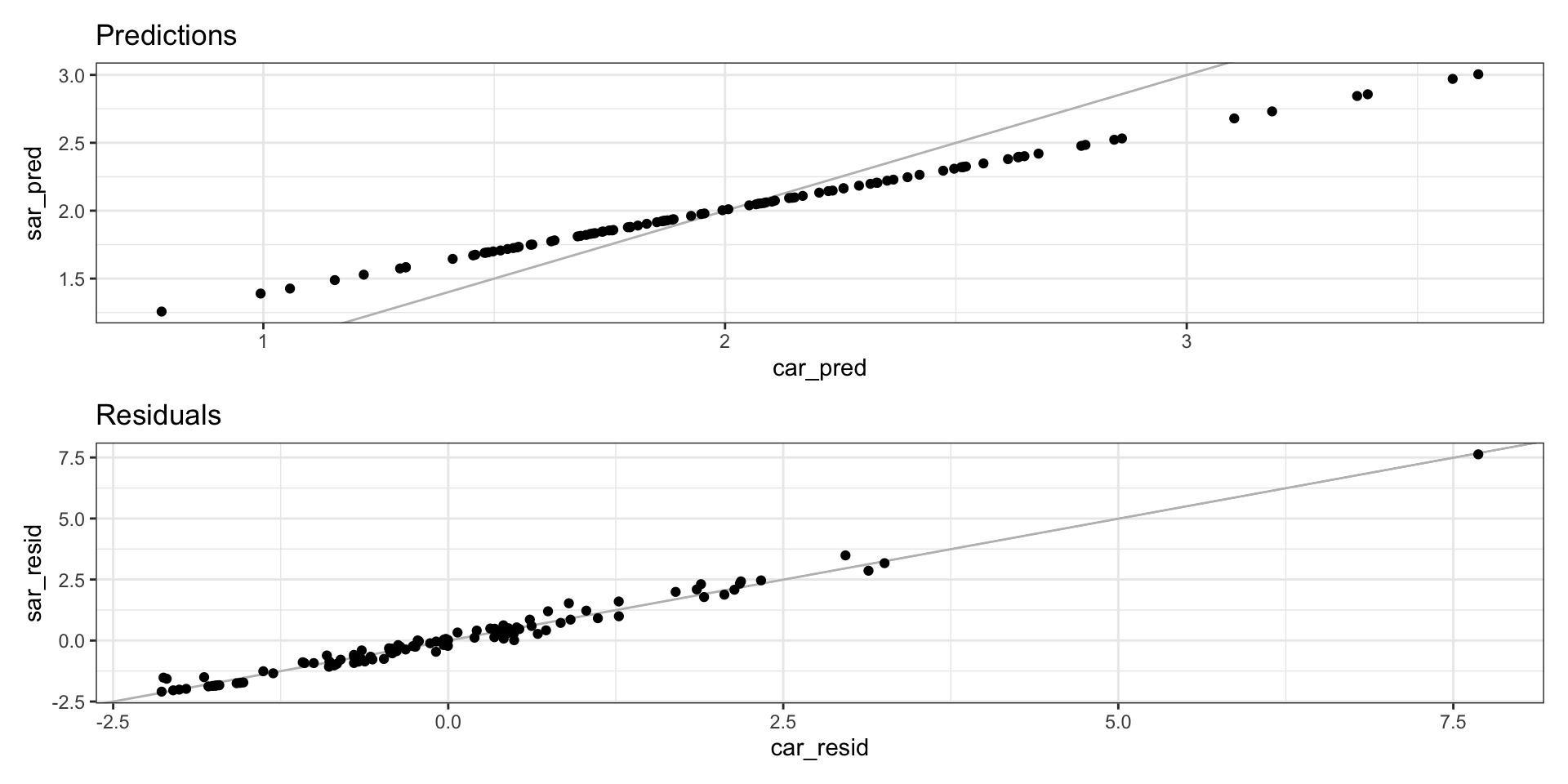
Comparing CAR vs SAR.
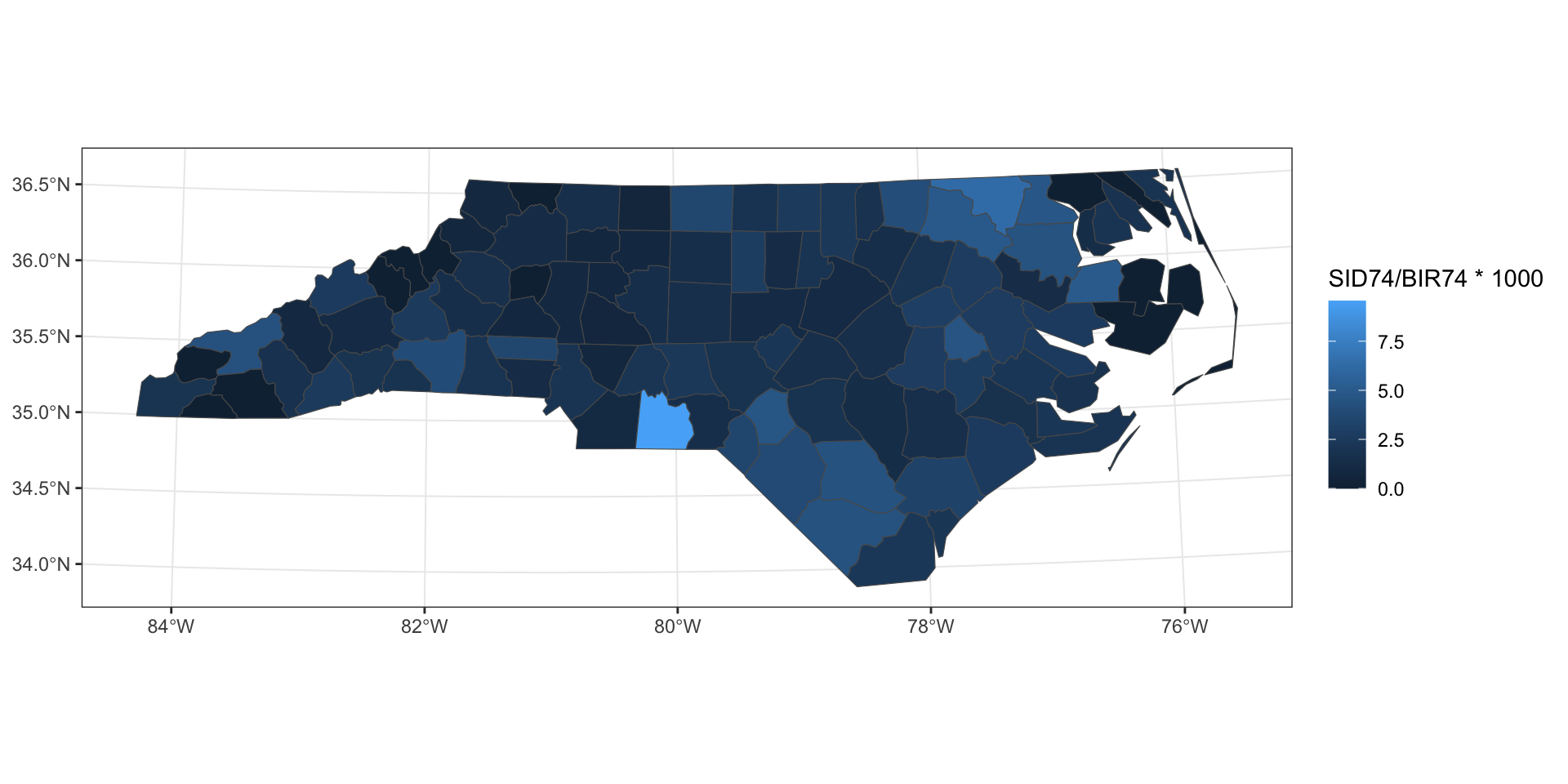
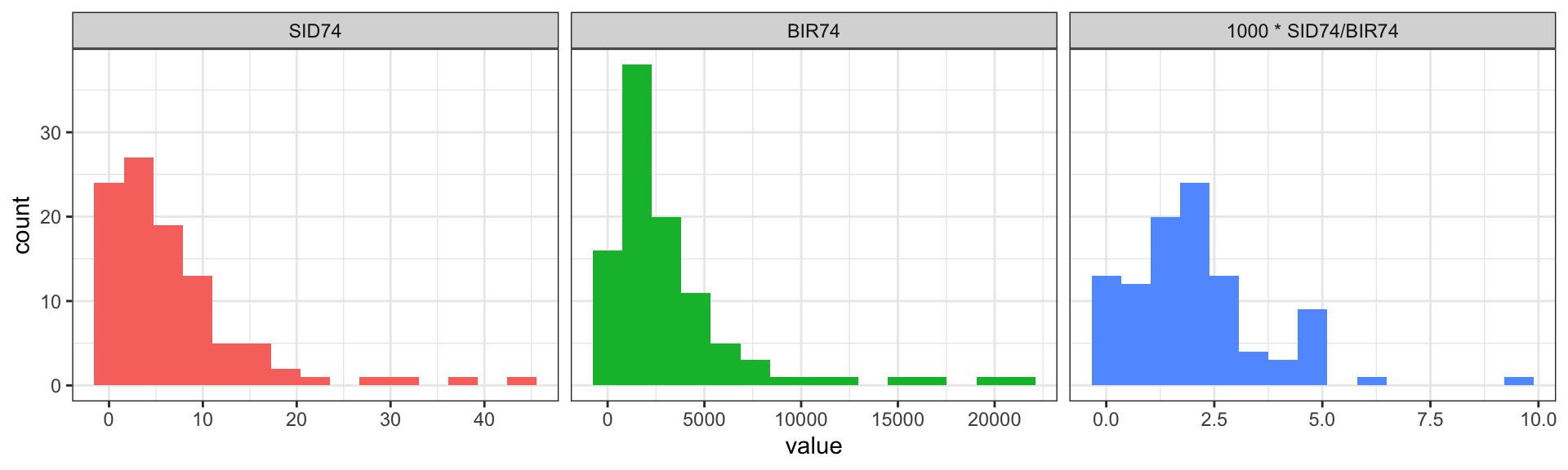
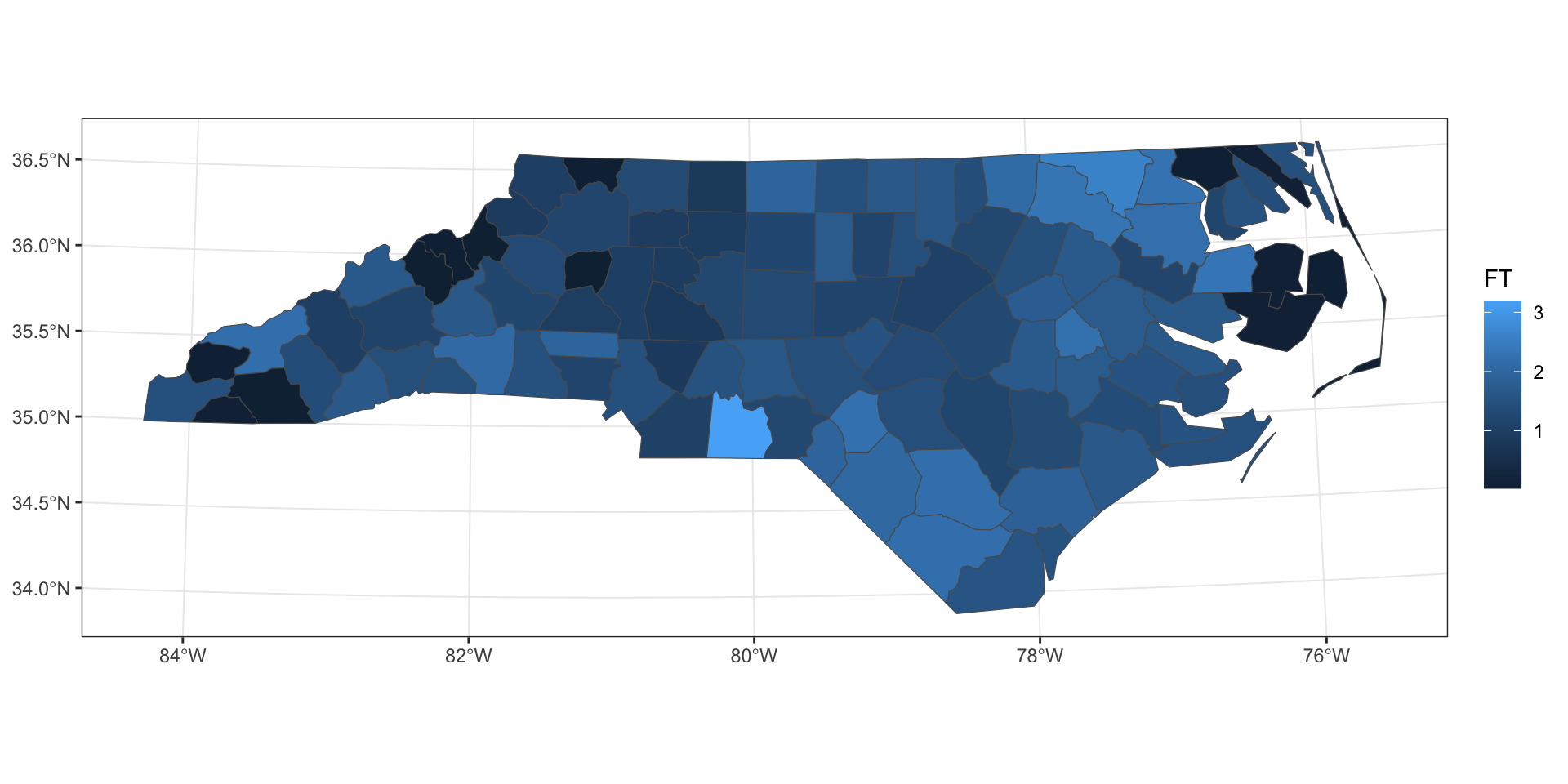
Freeman-Tukey’s transformation
This is the transformation used by Cressie and Road in Spatial Data Analysis of Regional Counts (1989).
\[ FT = \sqrt{1000} \left( \sqrt{\frac{SID74}{BIR74}} + \sqrt{\frac{SID74+1}{BIR74}} \right) \]
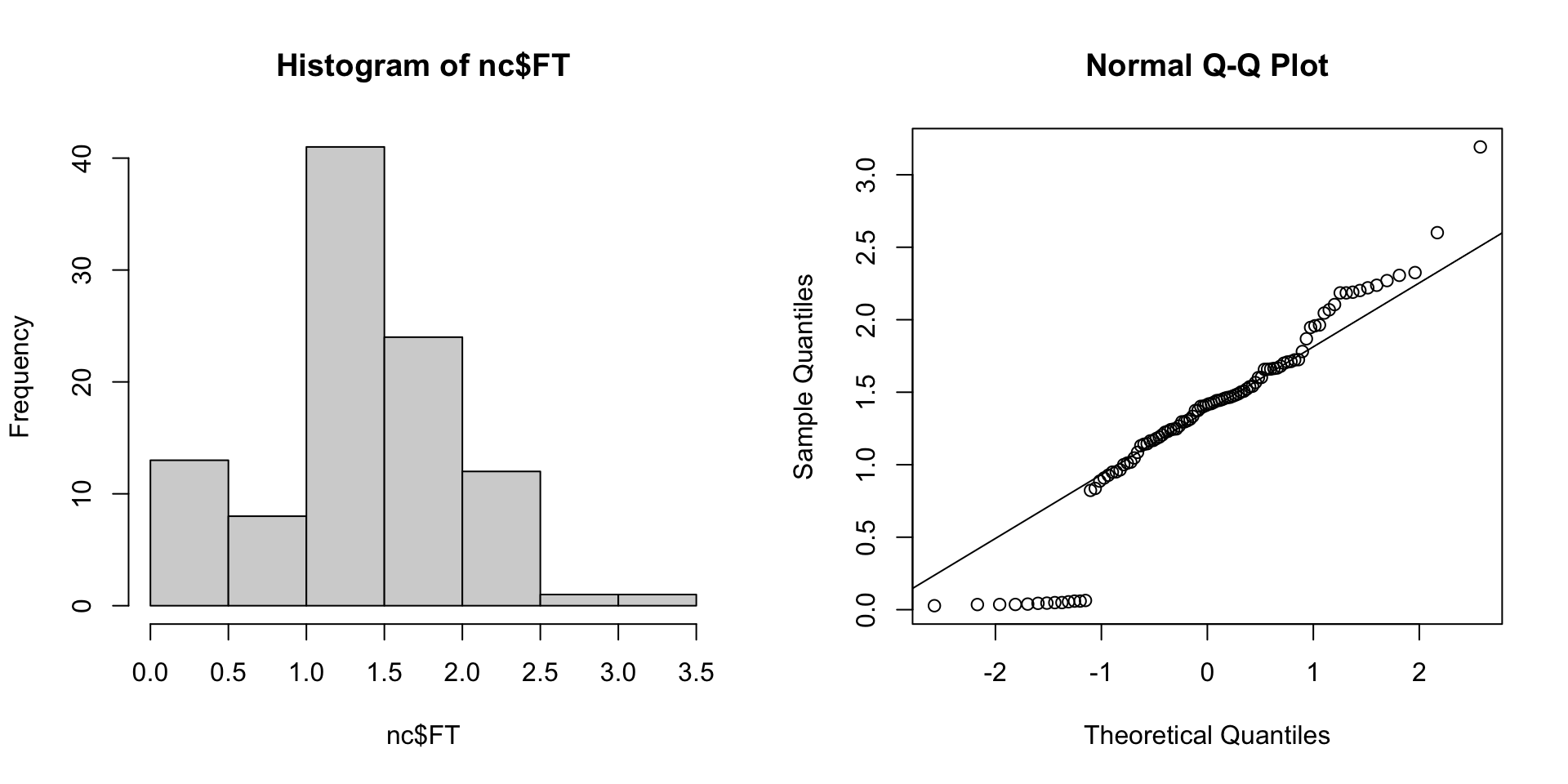
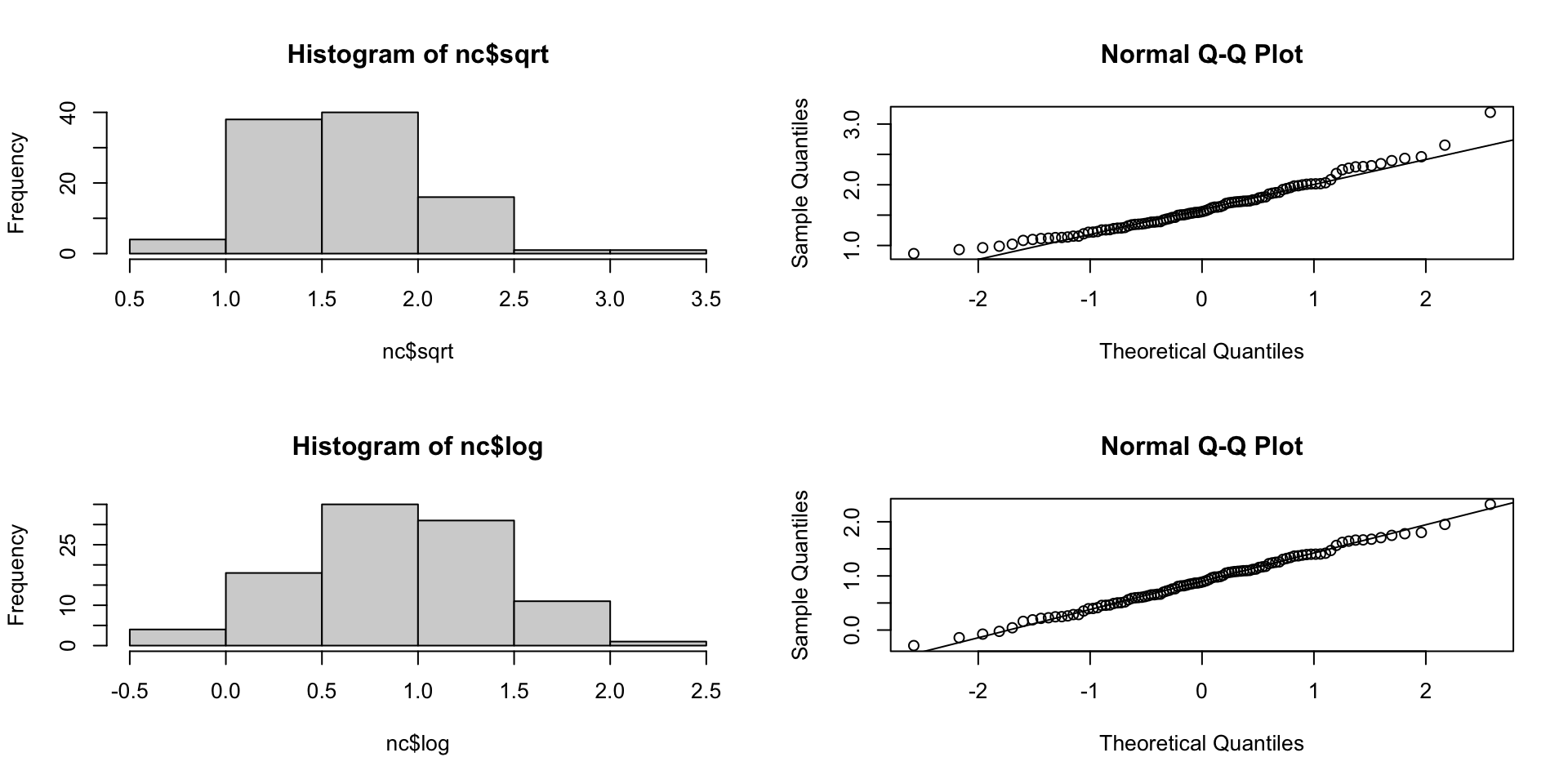
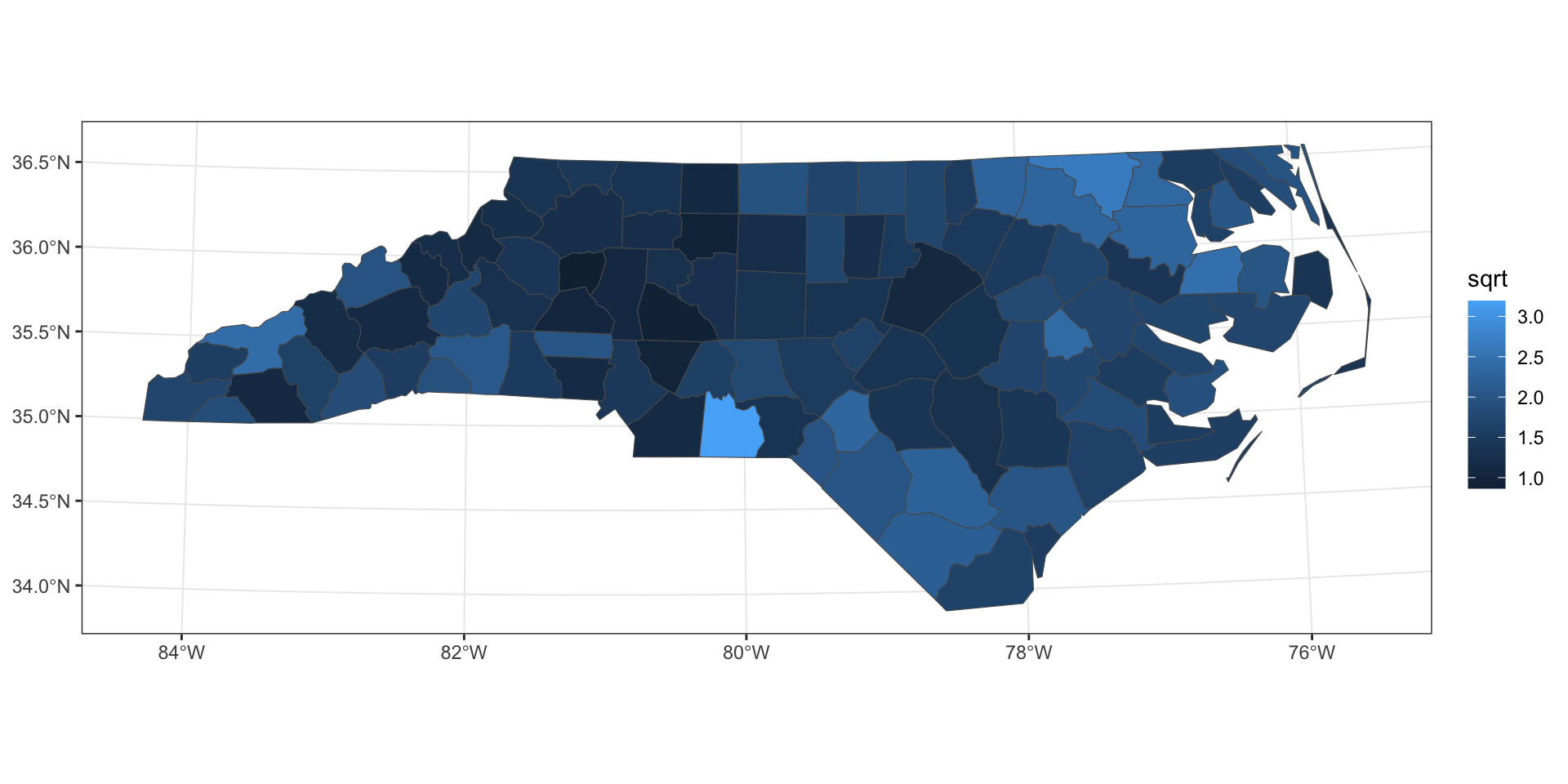
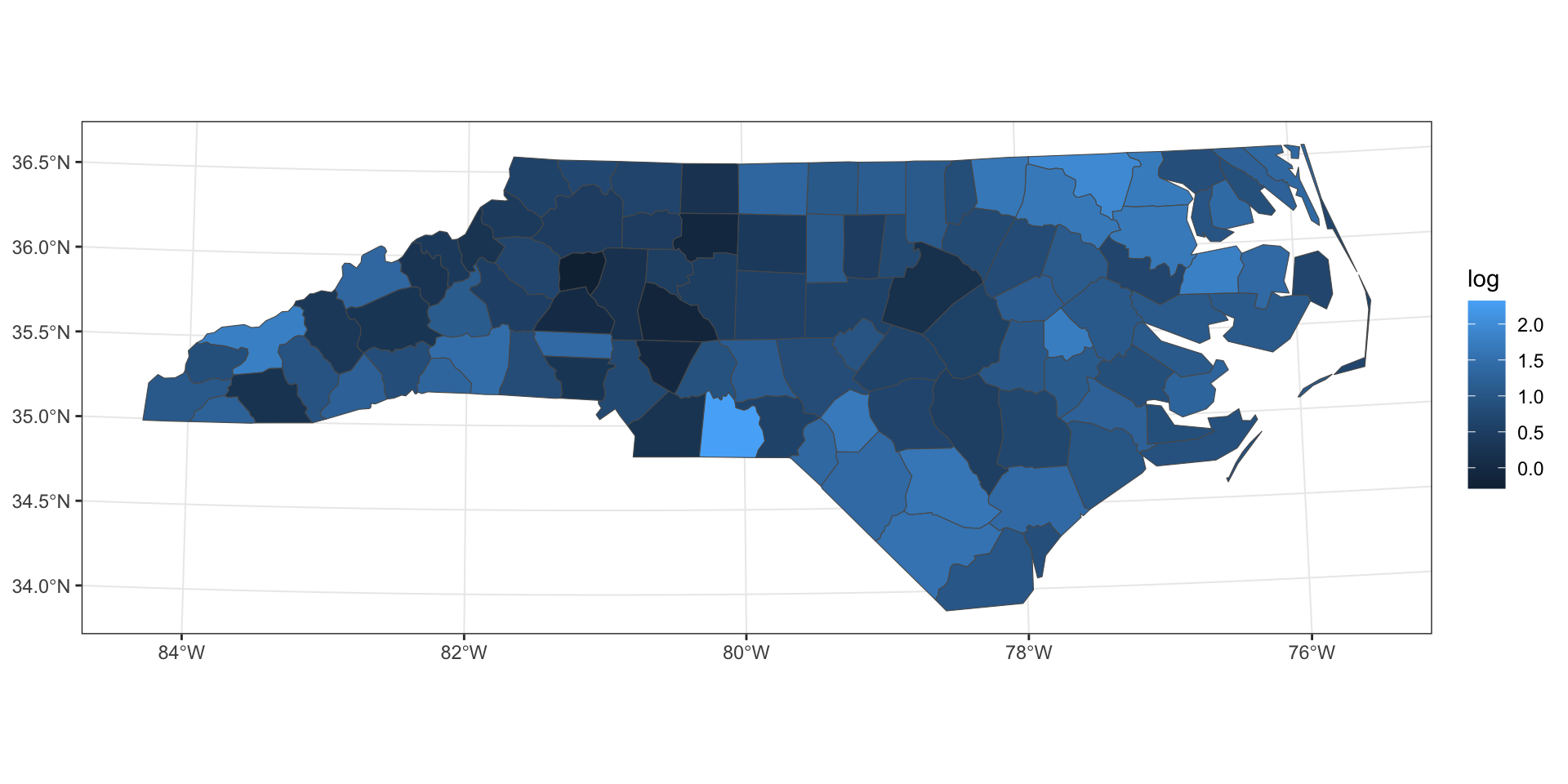
Other possibilities
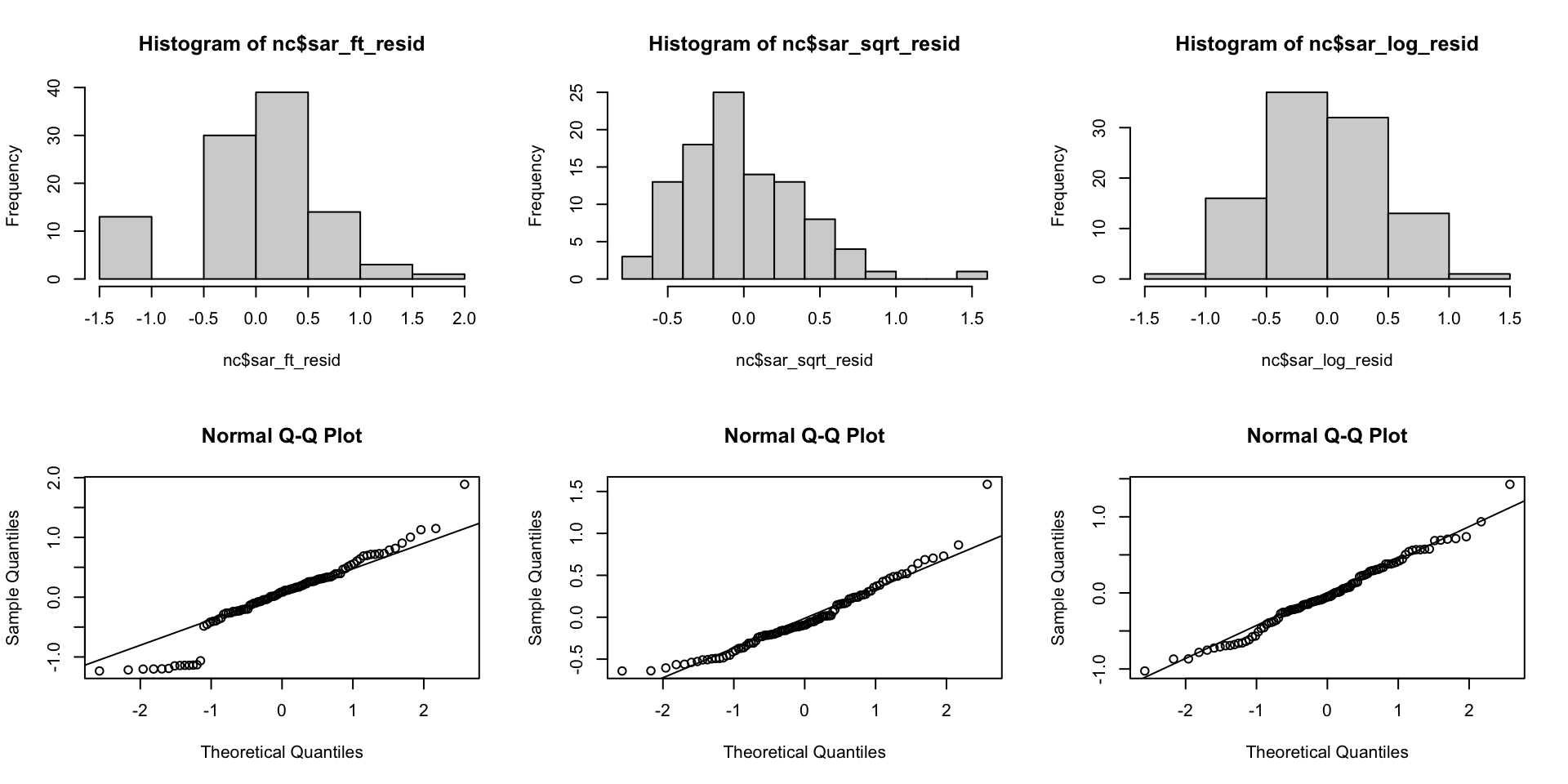
FT transformation
sqrt transformation
log transformation
CAR predictions
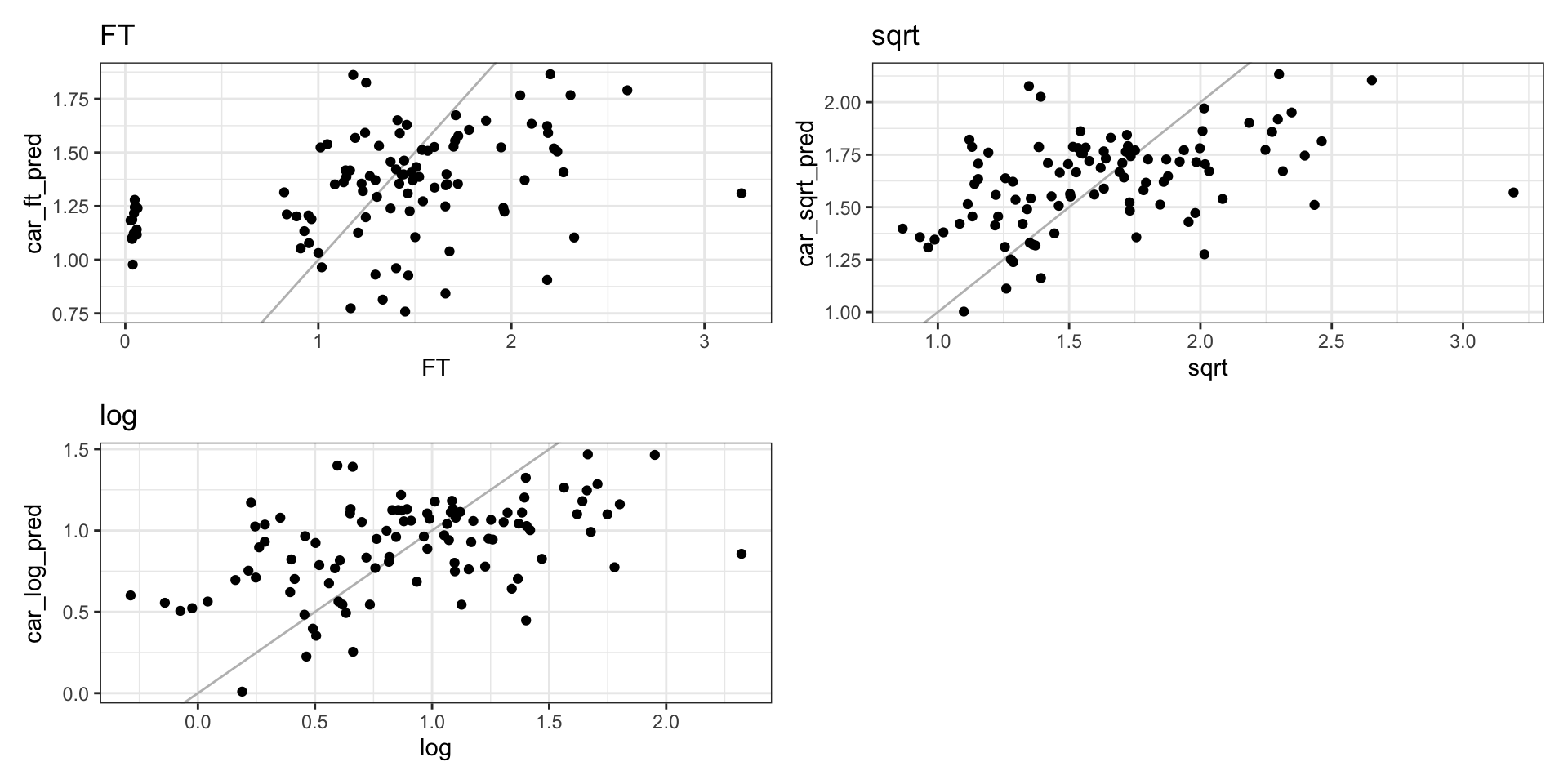
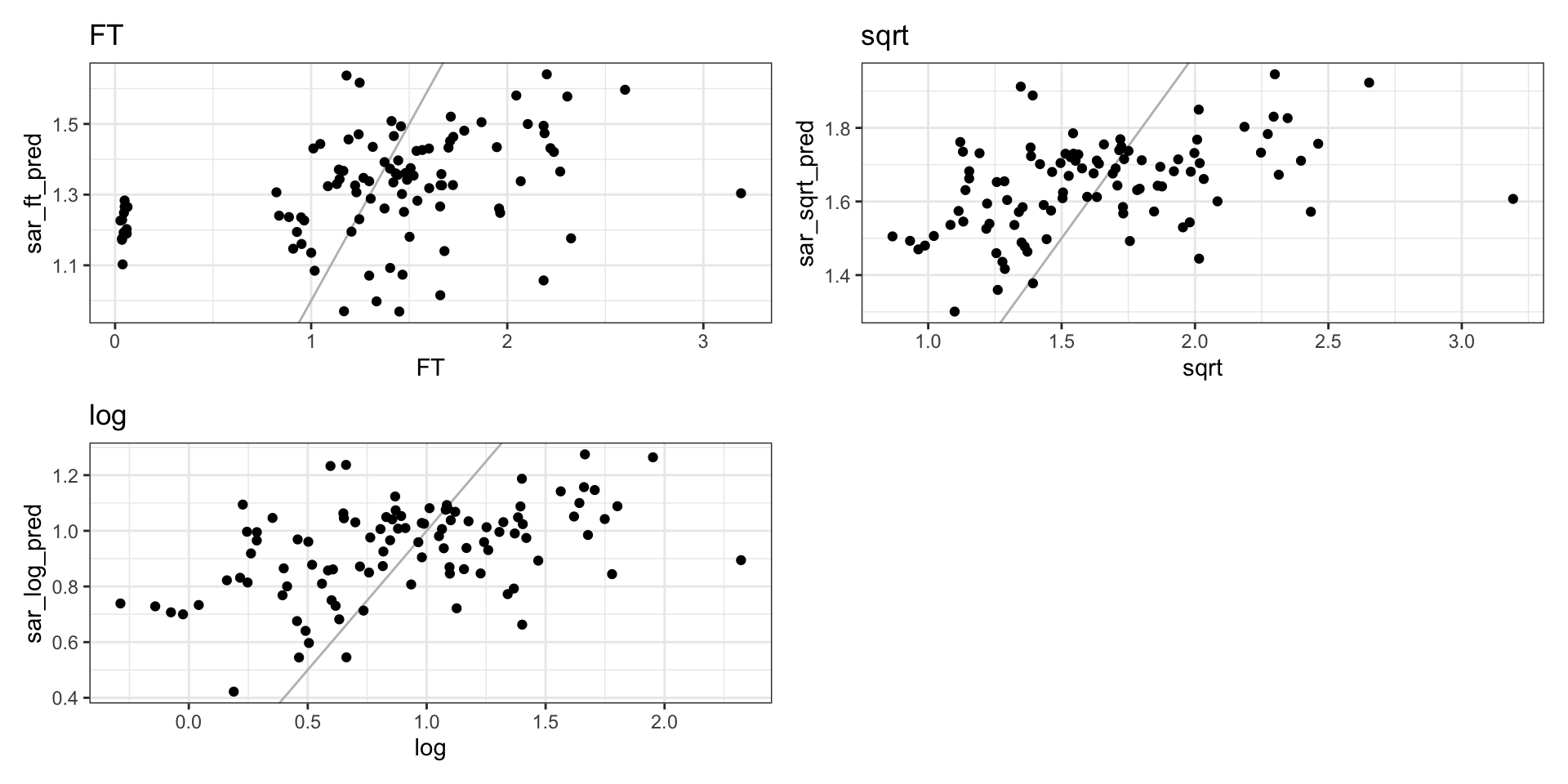
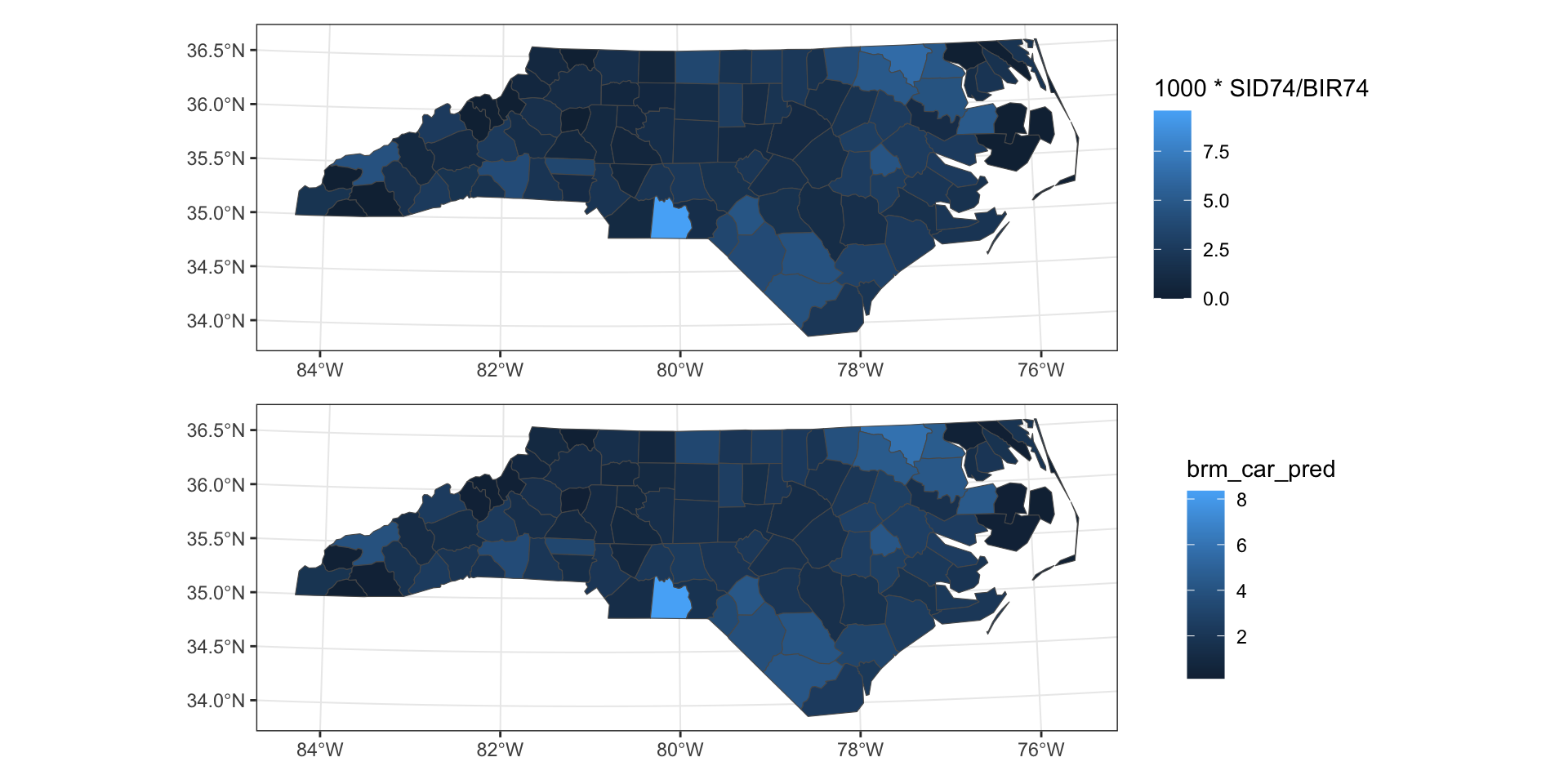
SAR predictions
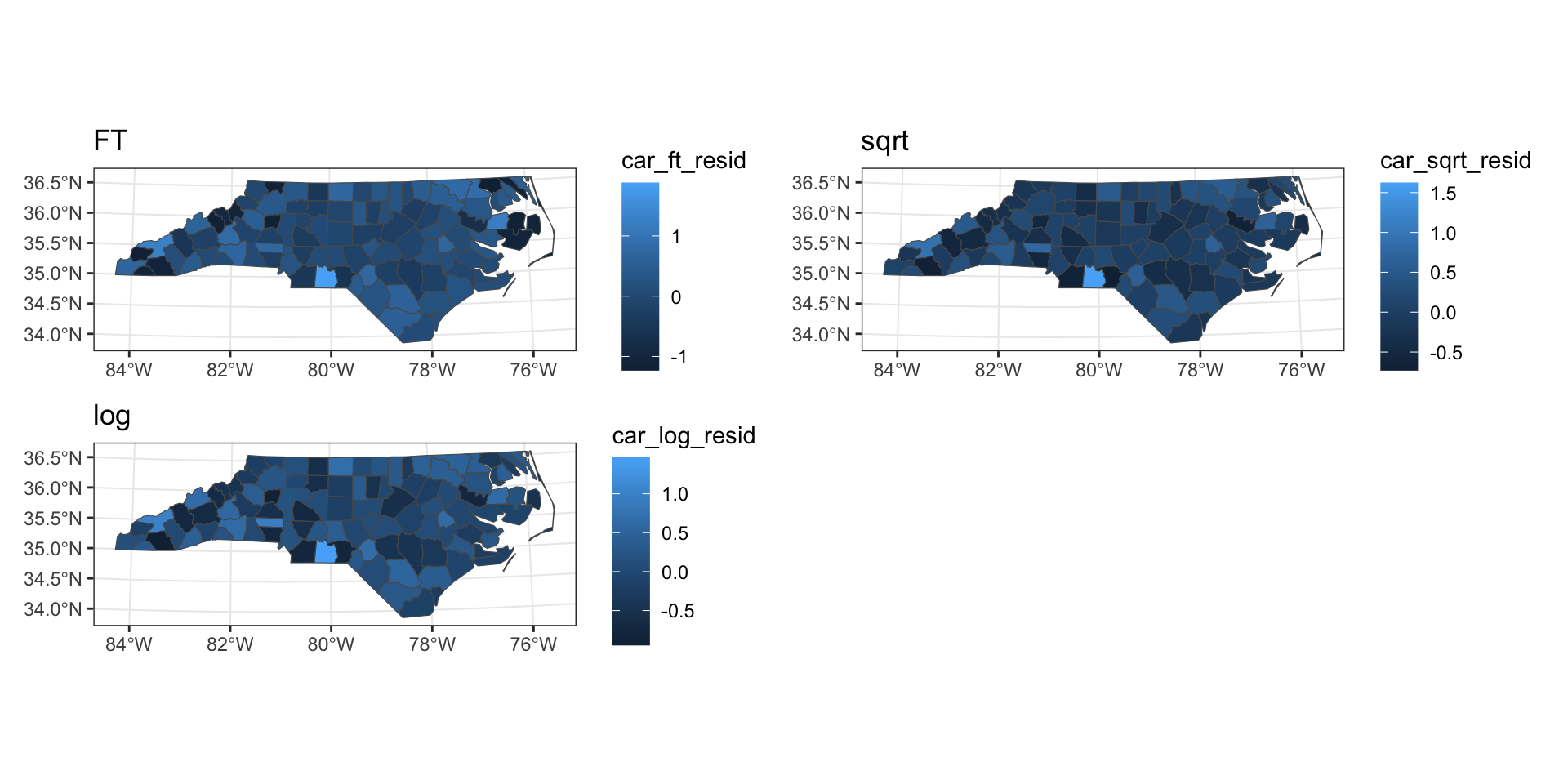
CAR residuals
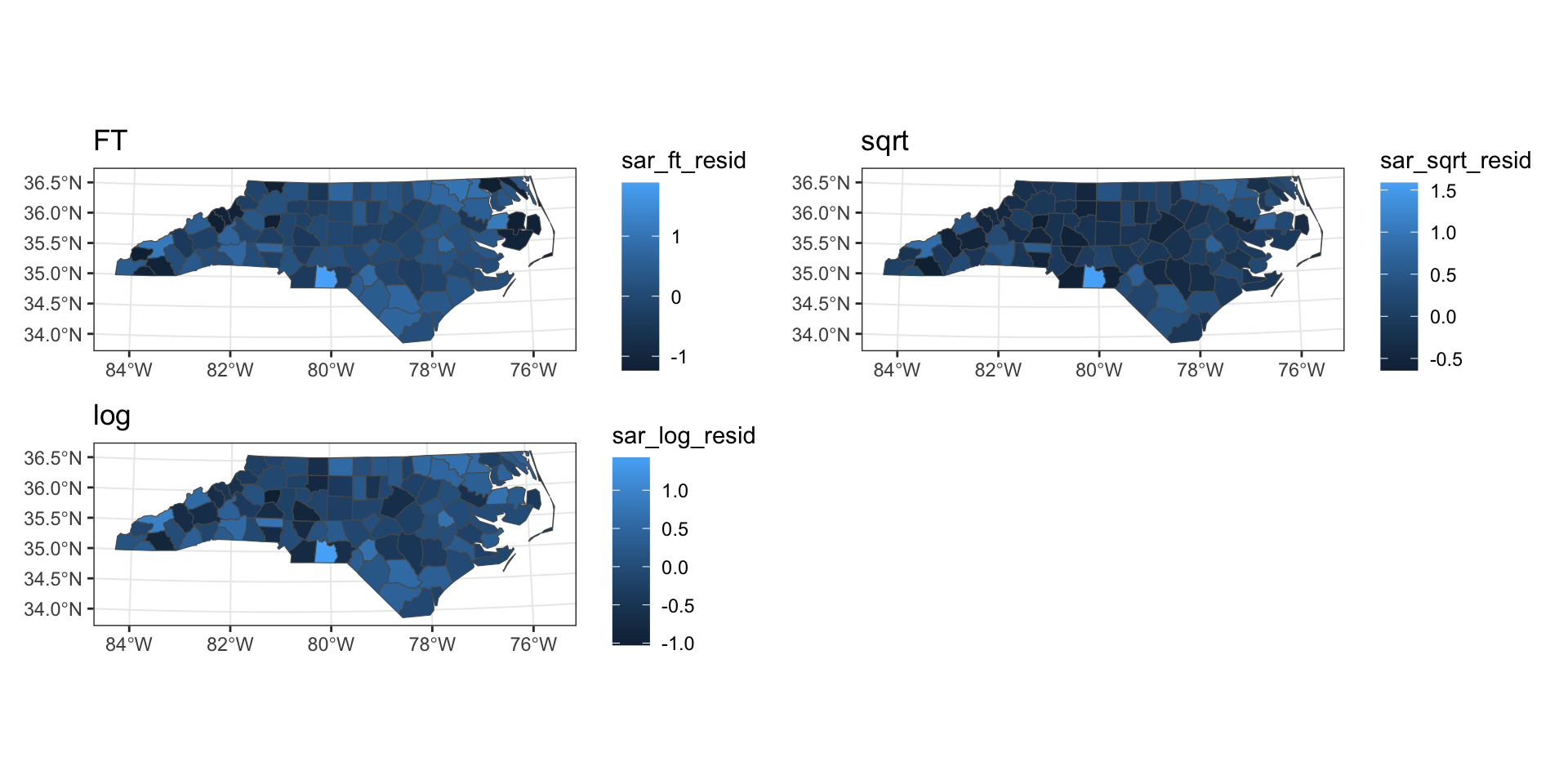
SAR predictions
CAR residual distributions
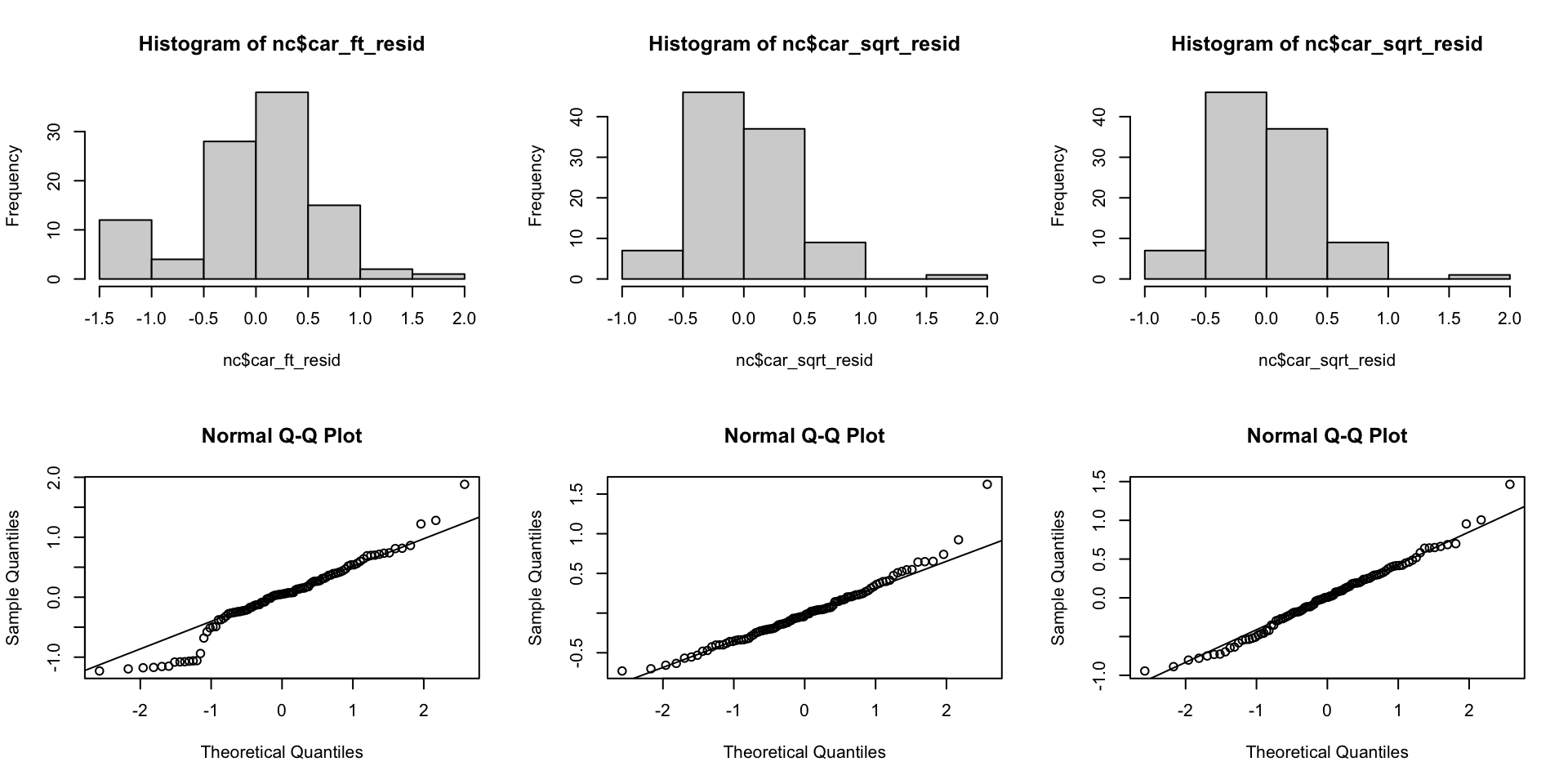
SAR residual distributions
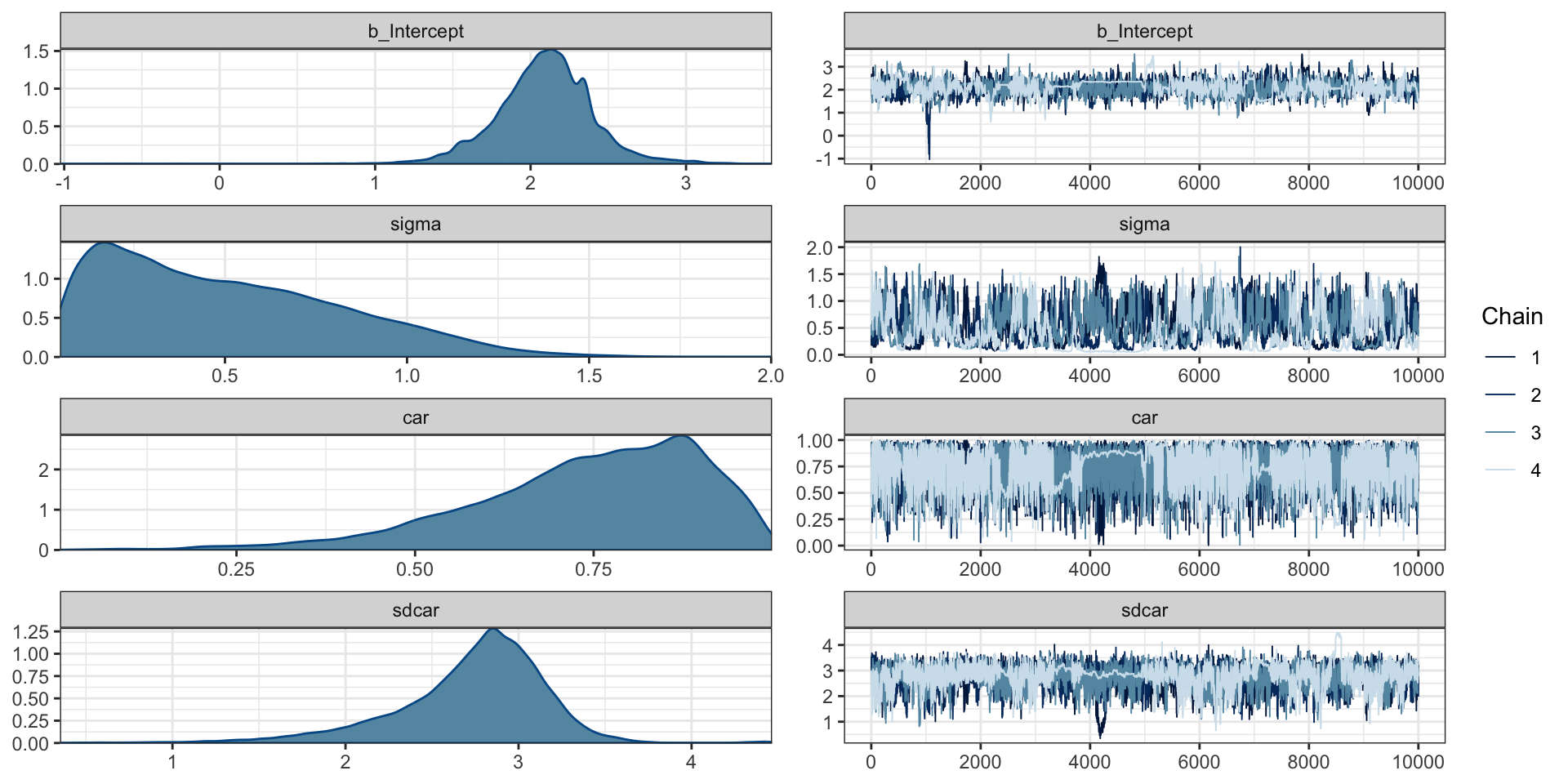
Diagnostics
Predictions
Observed vs predicted
Diagnostics
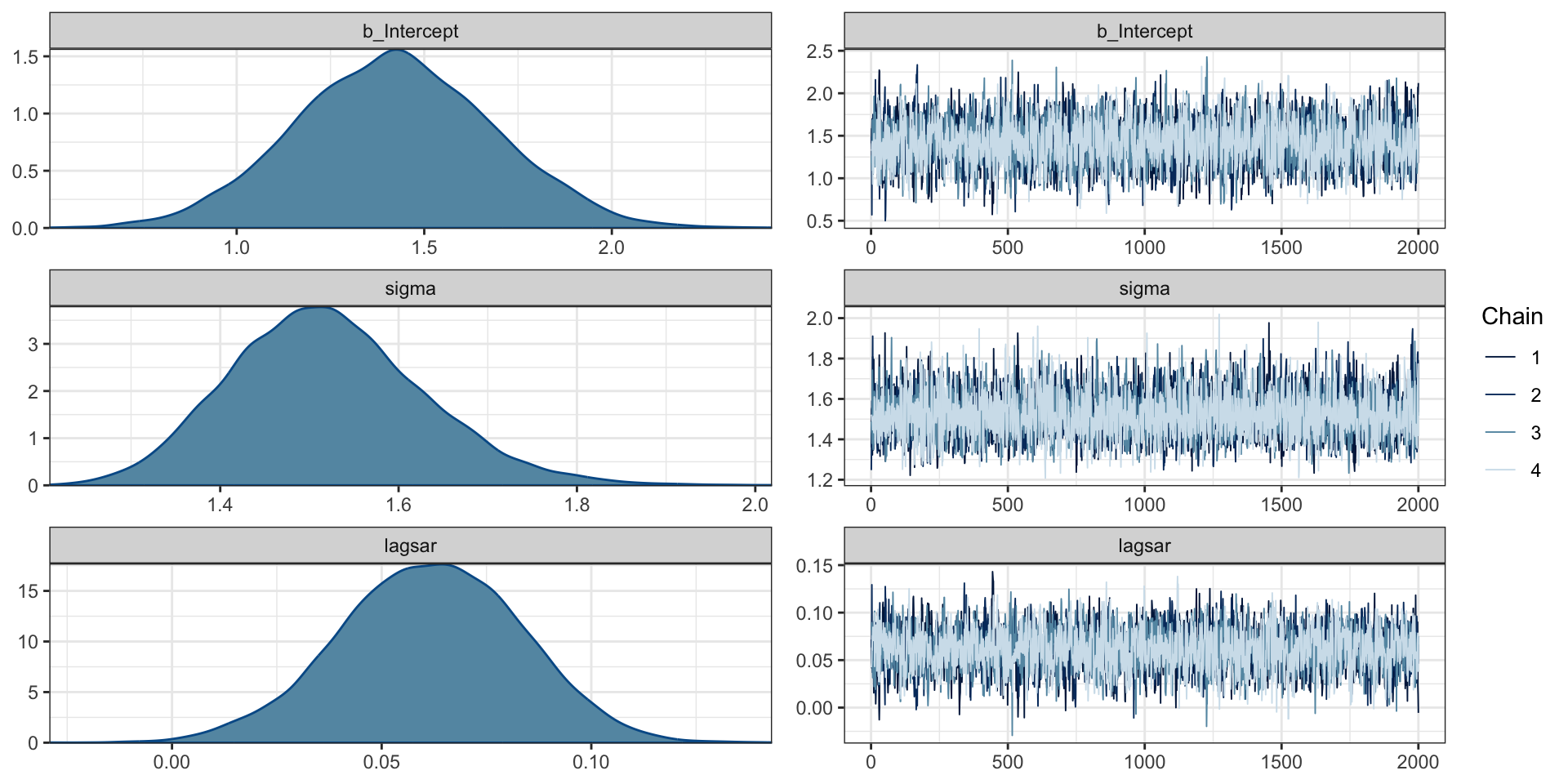
Predictions
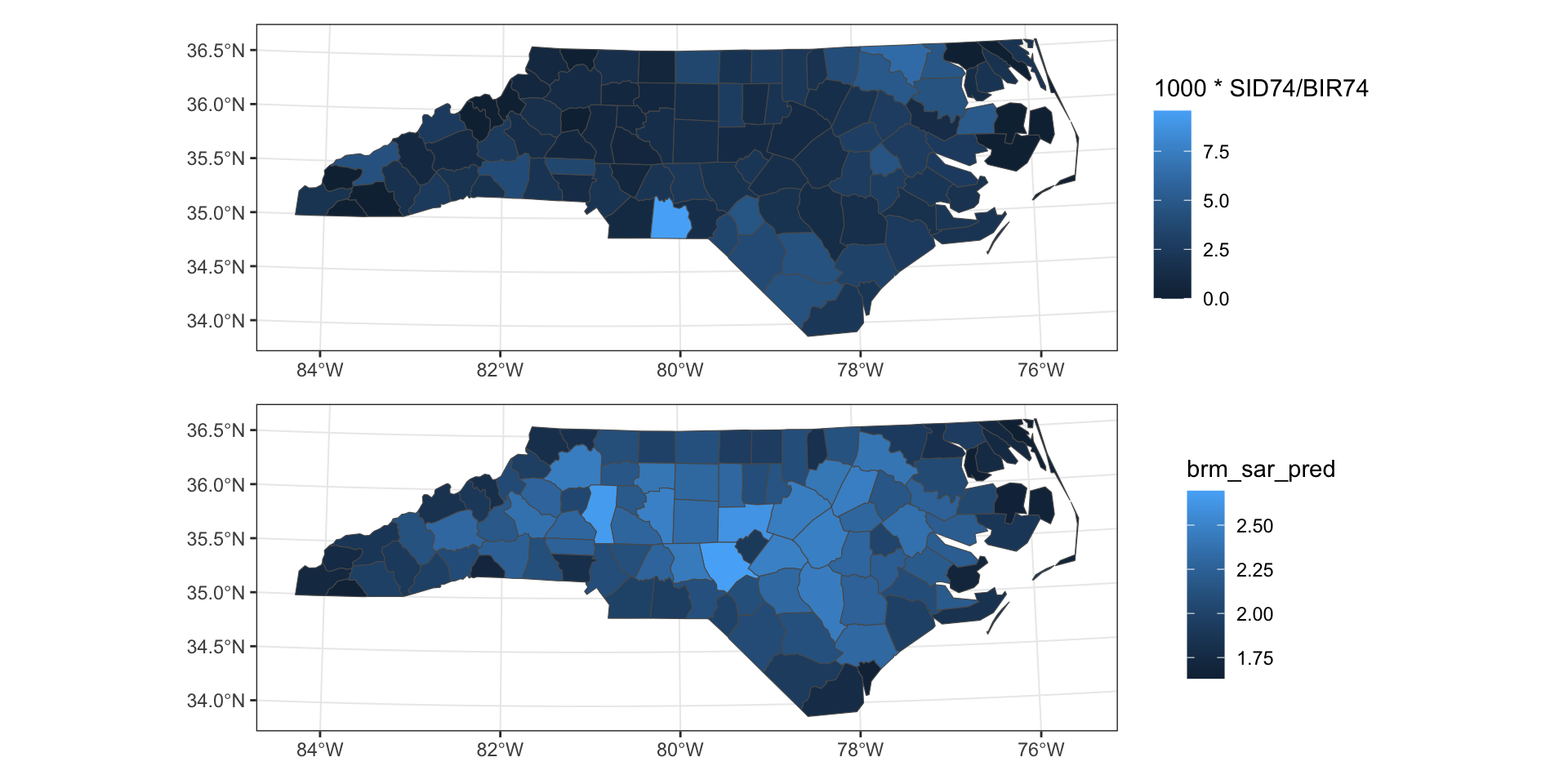
Observed vs predicted