Jan Feb Mar Apr May Jun
1959 315.42 316.31 316.50 317.56 318.13 318.00
1960 316.27 316.81 317.42 318.87 319.87 319.43
1961 316.73 317.54 318.38 319.31 320.42 319.61
1962 317.78 318.40 319.53 320.42 320.85 320.45
1963 318.58 318.92 319.70 321.22 322.08 321.31
1964 319.41 320.07 320.74 321.40 322.06 321.73
1965 319.27 320.28 320.73 321.97 322.00 321.71
1966 320.46 321.43 322.23 323.54 323.91 323.59
1967 322.17 322.34 322.88 324.25 324.83 323.93
1968 322.40 322.99 323.73 324.86 325.40 325.20
1969 323.83 324.26 325.47 326.50 327.21 326.54
1970 324.89 325.82 326.77 327.97 327.91 327.50
1971 326.01 326.51 327.01 327.62 328.76 328.40
1972 326.60 327.47 327.58 329.56 329.90 328.92
1973 328.37 329.40 330.14 331.33 332.31 331.90
1974 329.18 330.55 331.32 332.48 332.92 332.08
1975 330.23 331.25 331.87 333.14 333.80 333.43
1976 331.58 332.39 333.33 334.41 334.71 334.17
1977 332.75 333.24 334.53 335.90 336.57 336.10
1978 334.80 335.22 336.47 337.59 337.84 337.72
1979 336.05 336.59 337.79 338.71 339.30 339.12
1980 337.84 338.19 339.91 340.60 341.29 341.00
1981 339.06 340.30 341.21 342.33 342.74 342.08
1982 340.57 341.44 342.53 343.39 343.96 343.18
1983 341.20 342.35 342.93 344.77 345.58 345.14
1984 343.52 344.33 345.11 346.88 347.25 346.62
1985 344.79 345.82 347.25 348.17 348.74 348.07
1986 346.11 346.78 347.68 349.37 350.03 349.37
1987 347.84 348.29 349.23 350.80 351.66 351.07
1988 350.25 351.54 352.05 353.41 354.04 353.62
1989 352.60 352.92 353.53 355.26 355.52 354.97
1990 353.50 354.55 355.23 356.04 357.00 356.07
1991 354.59 355.63 357.03 358.48 359.22 358.12
1992 355.88 356.63 357.72 359.07 359.58 359.17
1993 356.63 357.10 358.32 359.41 360.23 359.55
1994 358.34 358.89 359.95 361.25 361.67 360.94
1995 359.98 361.03 361.66 363.48 363.82 363.30
1996 362.09 363.29 364.06 364.76 365.45 365.01
1997 363.23 364.06 364.61 366.40 366.84 365.68
Jul Aug Sep Oct Nov Dec
1959 316.39 314.65 313.68 313.18 314.66 315.43
1960 318.01 315.74 314.00 313.68 314.84 316.03
1961 318.42 316.63 314.83 315.16 315.94 316.85
1962 319.45 317.25 316.11 315.27 316.53 317.53
1963 319.58 317.61 316.05 315.83 316.91 318.20
1964 320.27 318.54 316.54 316.71 317.53 318.55
1965 321.05 318.71 317.66 317.14 318.70 319.25
1966 322.24 320.20 318.48 317.94 319.63 320.87
1967 322.38 320.76 319.10 319.24 320.56 321.80
1968 323.98 321.95 320.18 320.09 321.16 322.74
1969 325.72 323.50 322.22 321.62 322.69 323.95
1970 326.18 324.53 322.93 322.90 323.85 324.96
1971 327.20 325.27 323.20 323.40 324.63 325.85
1972 327.88 326.16 324.68 325.04 326.34 327.39
1973 330.70 329.15 327.35 327.02 327.99 328.48
1974 331.01 329.23 327.27 327.21 328.29 329.41
1975 331.73 329.90 328.40 328.17 329.32 330.59
1976 332.89 330.77 329.14 328.78 330.14 331.52
1977 334.76 332.59 331.42 330.98 332.24 333.68
1978 336.37 334.51 332.60 332.38 333.75 334.78
1979 337.56 335.92 333.75 333.70 335.12 336.56
1980 339.39 337.43 335.72 335.84 336.93 338.04
1981 340.32 338.26 336.52 336.68 338.19 339.44
1982 341.88 339.65 337.81 337.69 339.09 340.32
1983 343.81 342.21 339.69 339.82 340.98 342.82
1984 345.22 343.11 340.90 341.18 342.80 344.04
1985 346.38 344.51 342.92 342.62 344.06 345.38
1986 347.76 345.73 344.68 343.99 345.48 346.72
1987 349.33 347.92 346.27 346.18 347.64 348.78
1988 352.22 350.27 348.55 348.72 349.91 351.18
1989 353.75 351.52 349.64 349.83 351.14 352.37
1990 354.67 352.76 350.82 351.04 352.69 354.07
1991 356.06 353.92 352.05 352.11 353.64 354.89
1992 356.94 354.92 352.94 353.23 354.09 355.33
1993 357.53 355.48 353.67 353.95 355.30 356.78
1994 359.55 357.49 355.84 356.00 357.59 359.05
1995 361.94 359.50 358.11 357.80 359.61 360.74
1996 363.70 361.54 359.51 359.65 360.80 362.38
1997 364.52 362.57 360.24 360.83 362.49 364.34tidyverts & prophet
Lecture 13
plotting tsibbles
As the tsibble is basically just a tibble which is basically just a data frame both base and ggplot plotting methods will work.
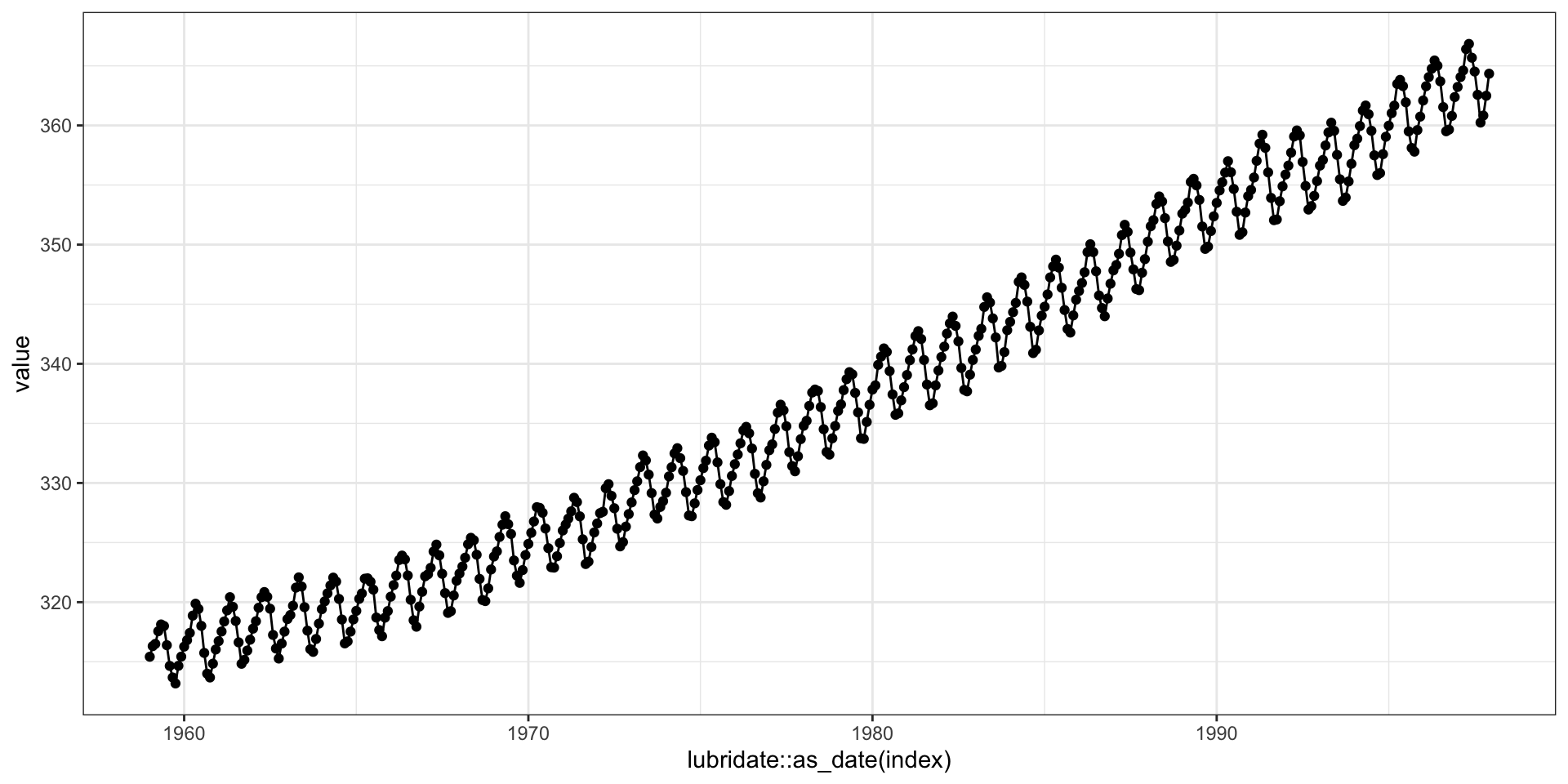
autoplot
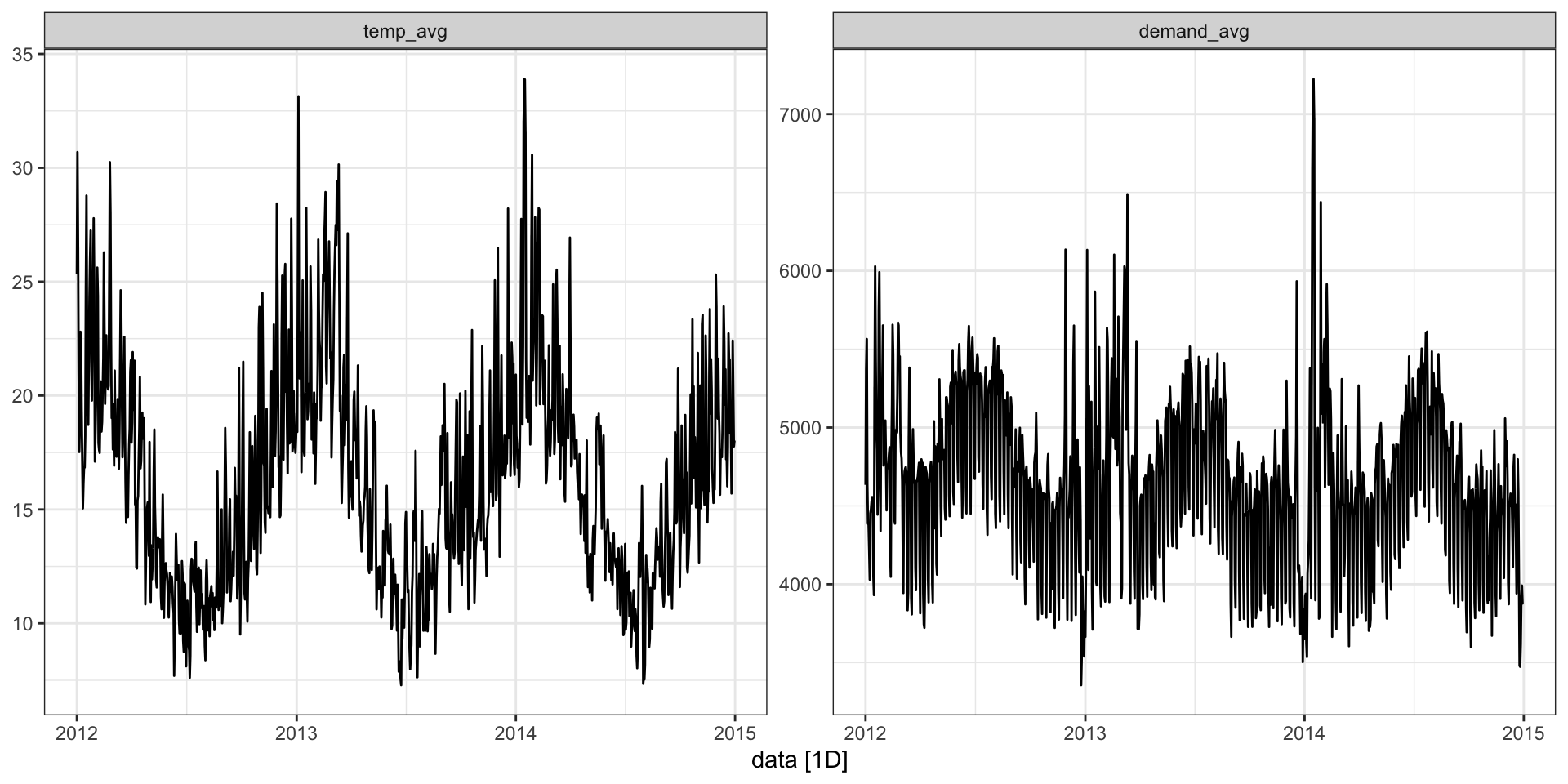
Multiple variables
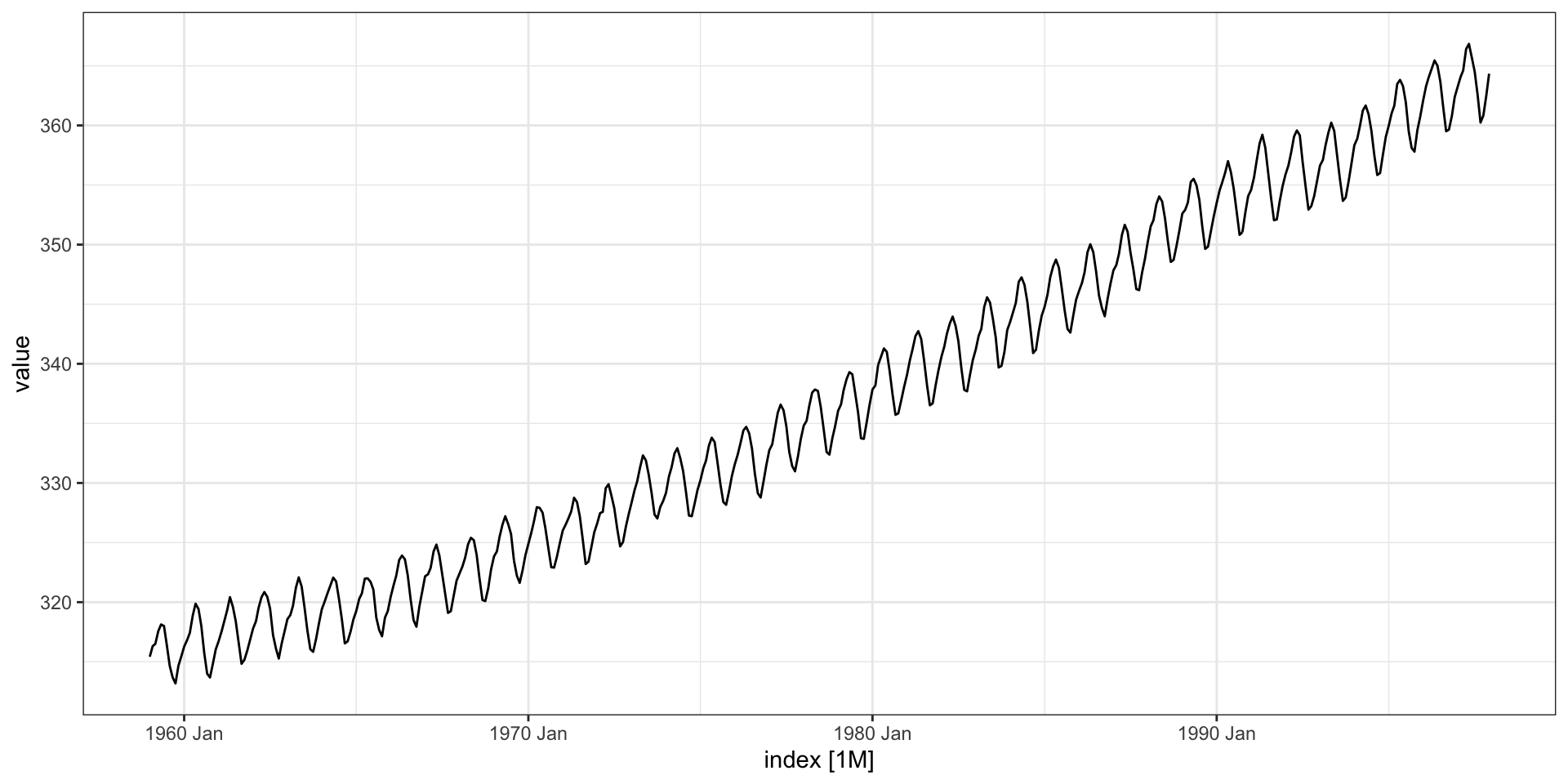
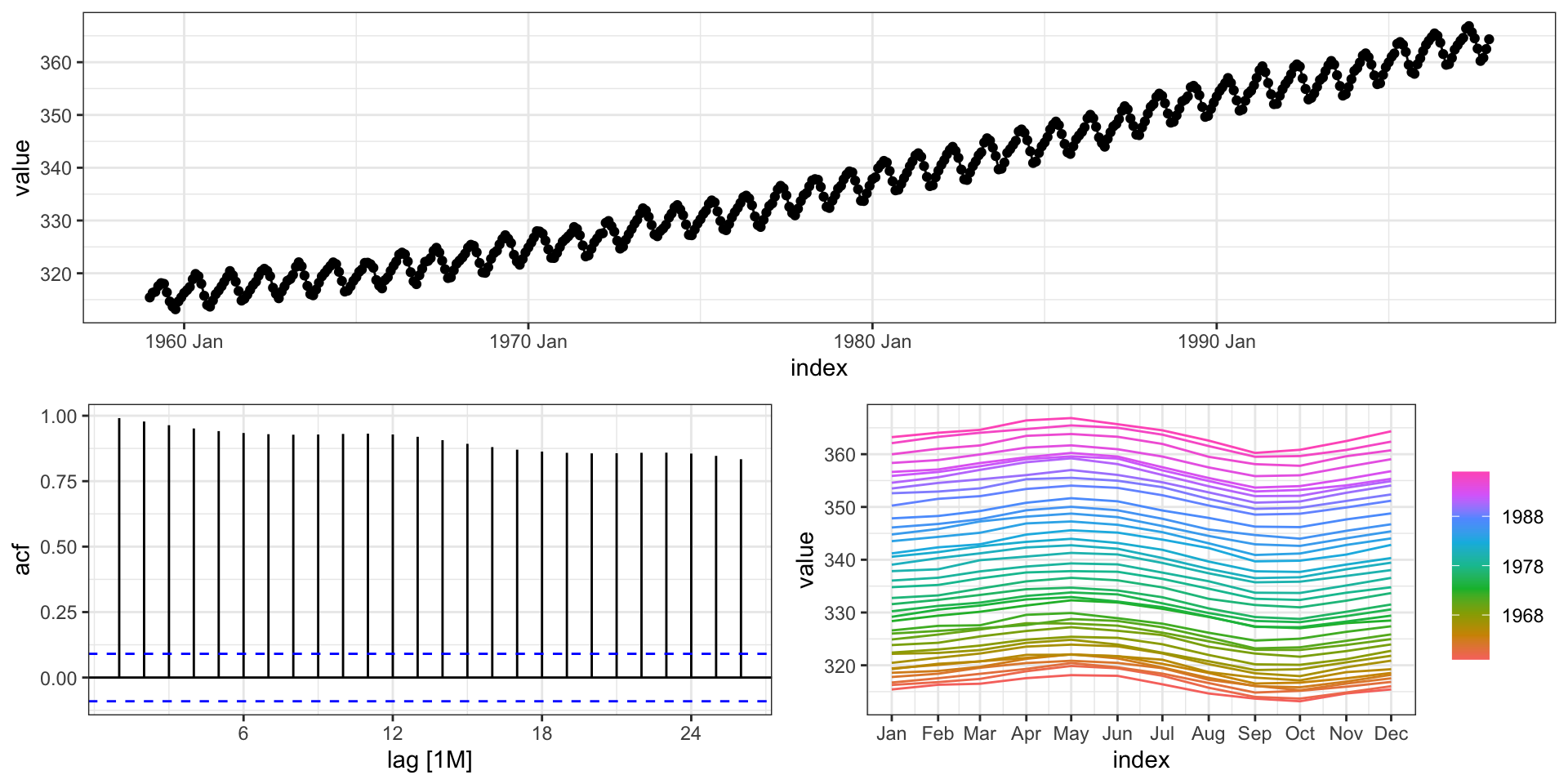
ggtsdisplay() replacement
The equivalent to the ggtsdisplay() plot is provided by feasts with gg_tsdisplay(),
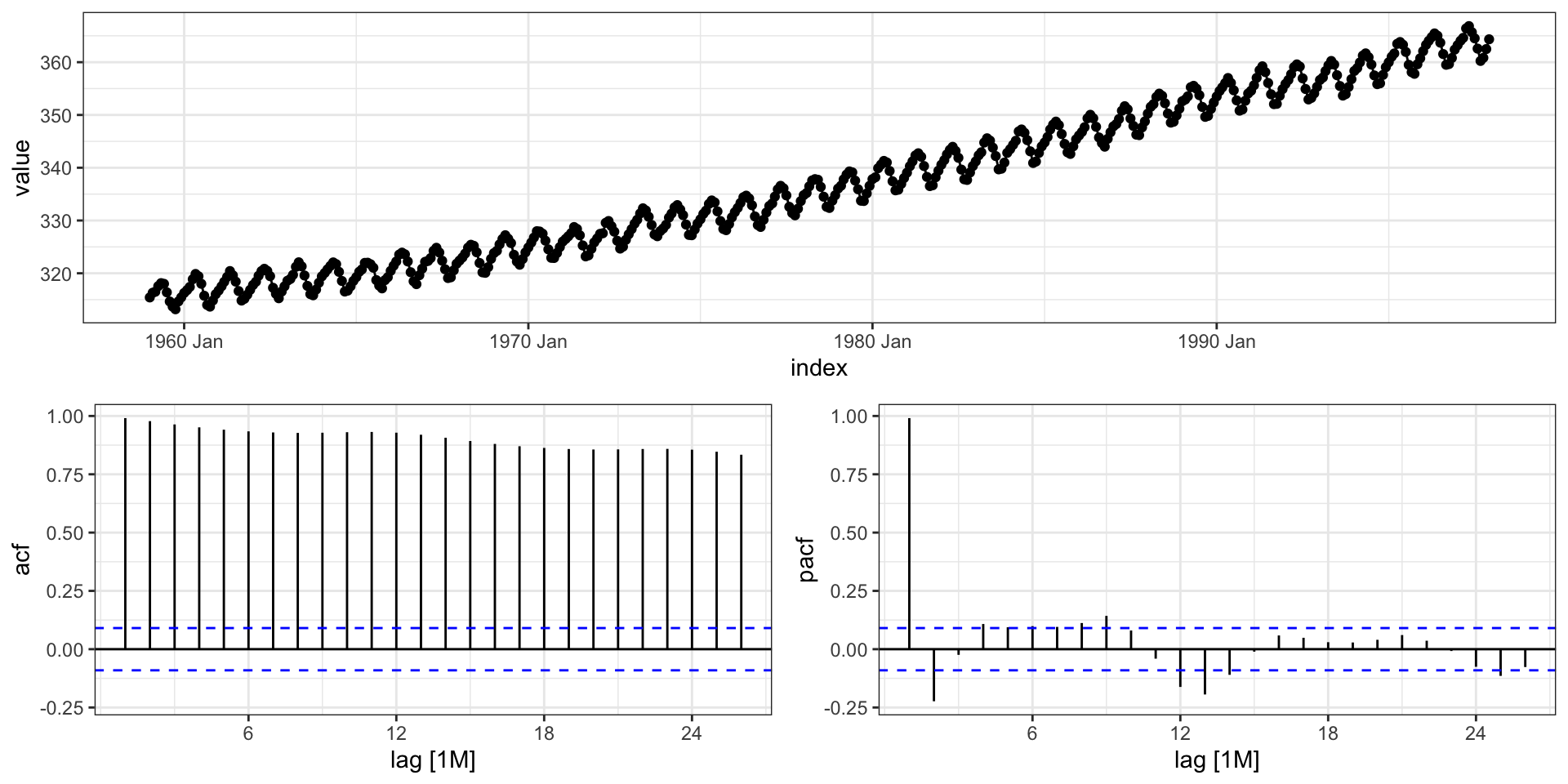
ggtsdisplay() - pACF
elec_sales
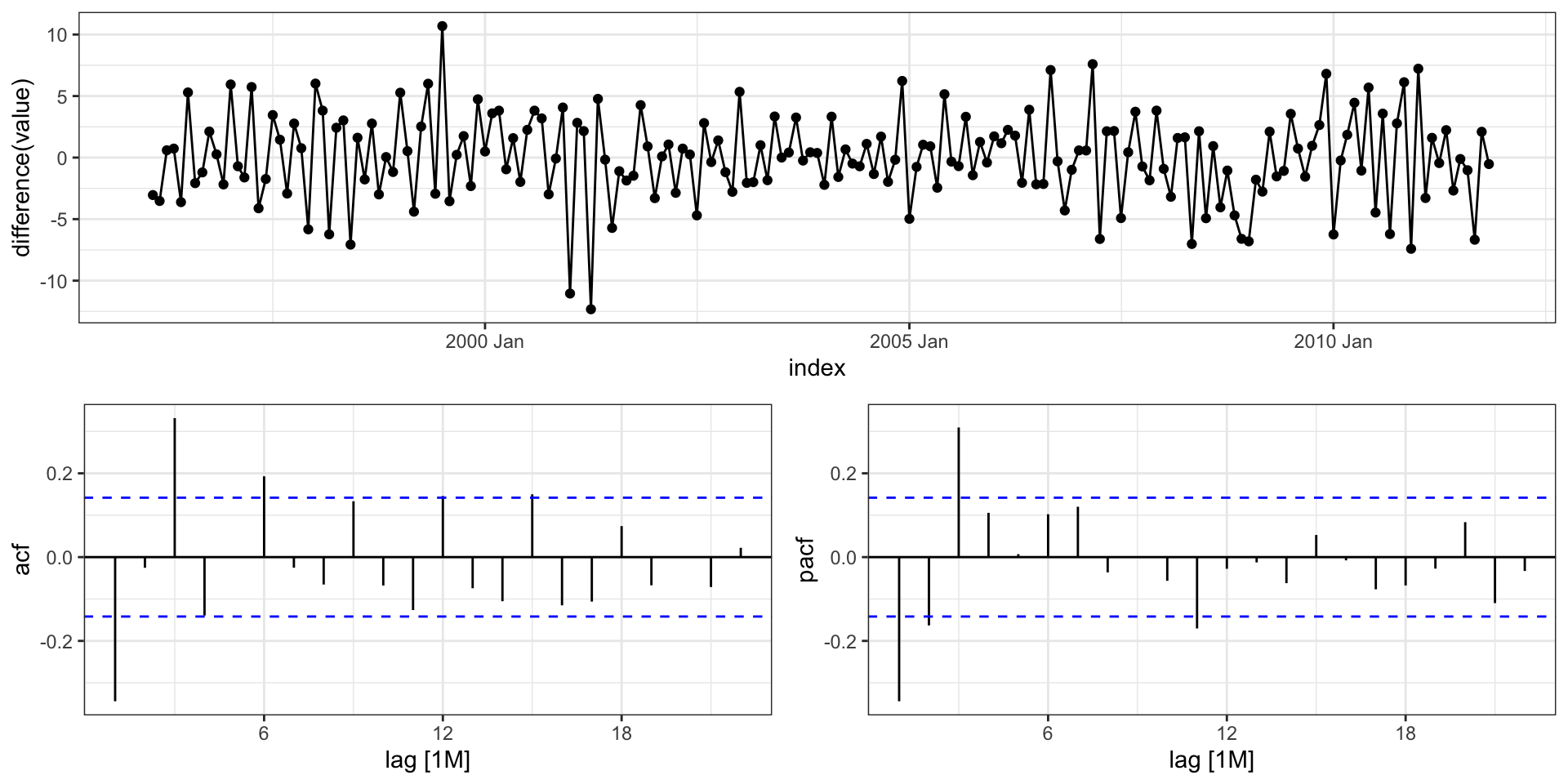
Differencing
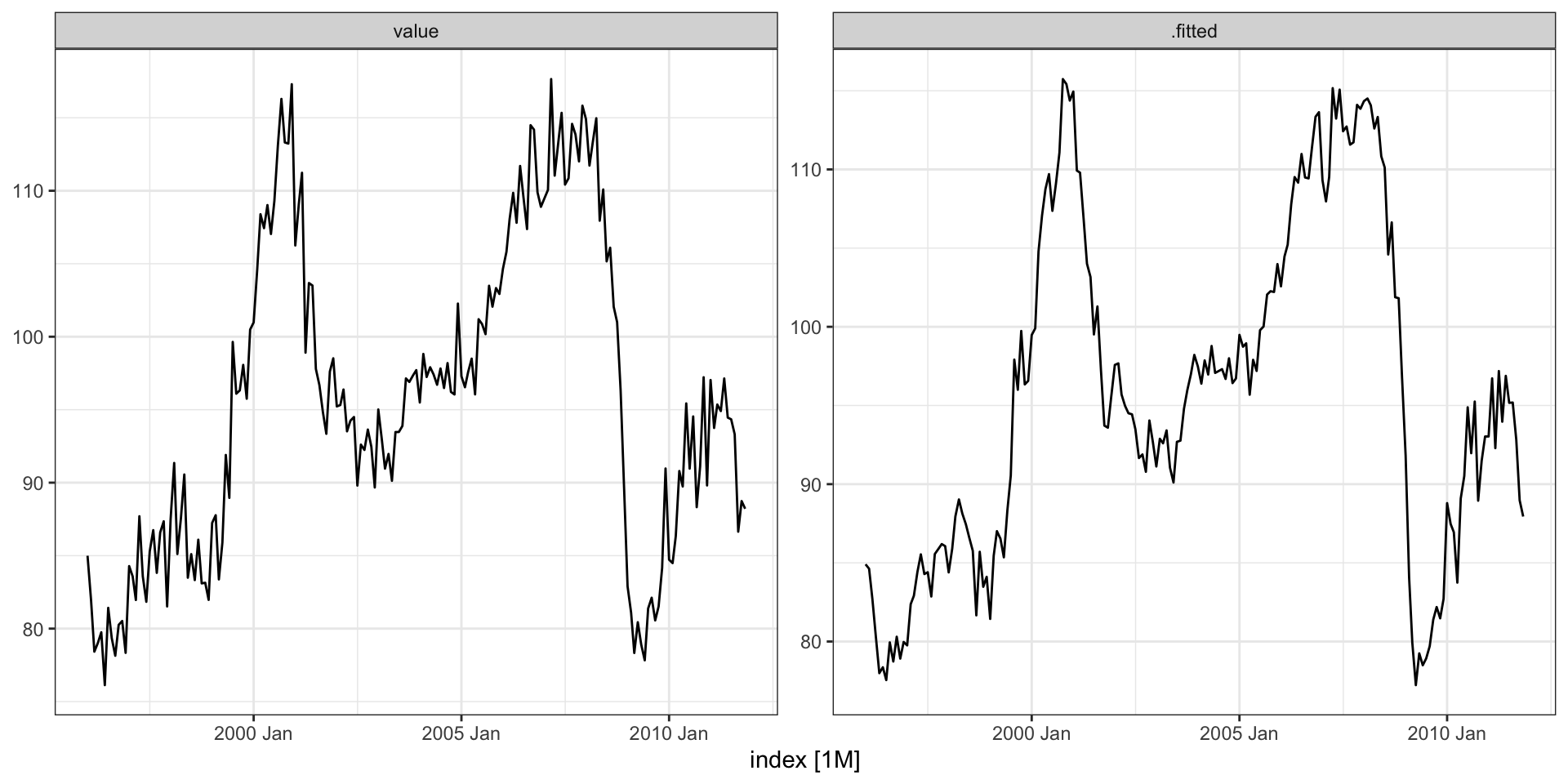
Observed vs predicted
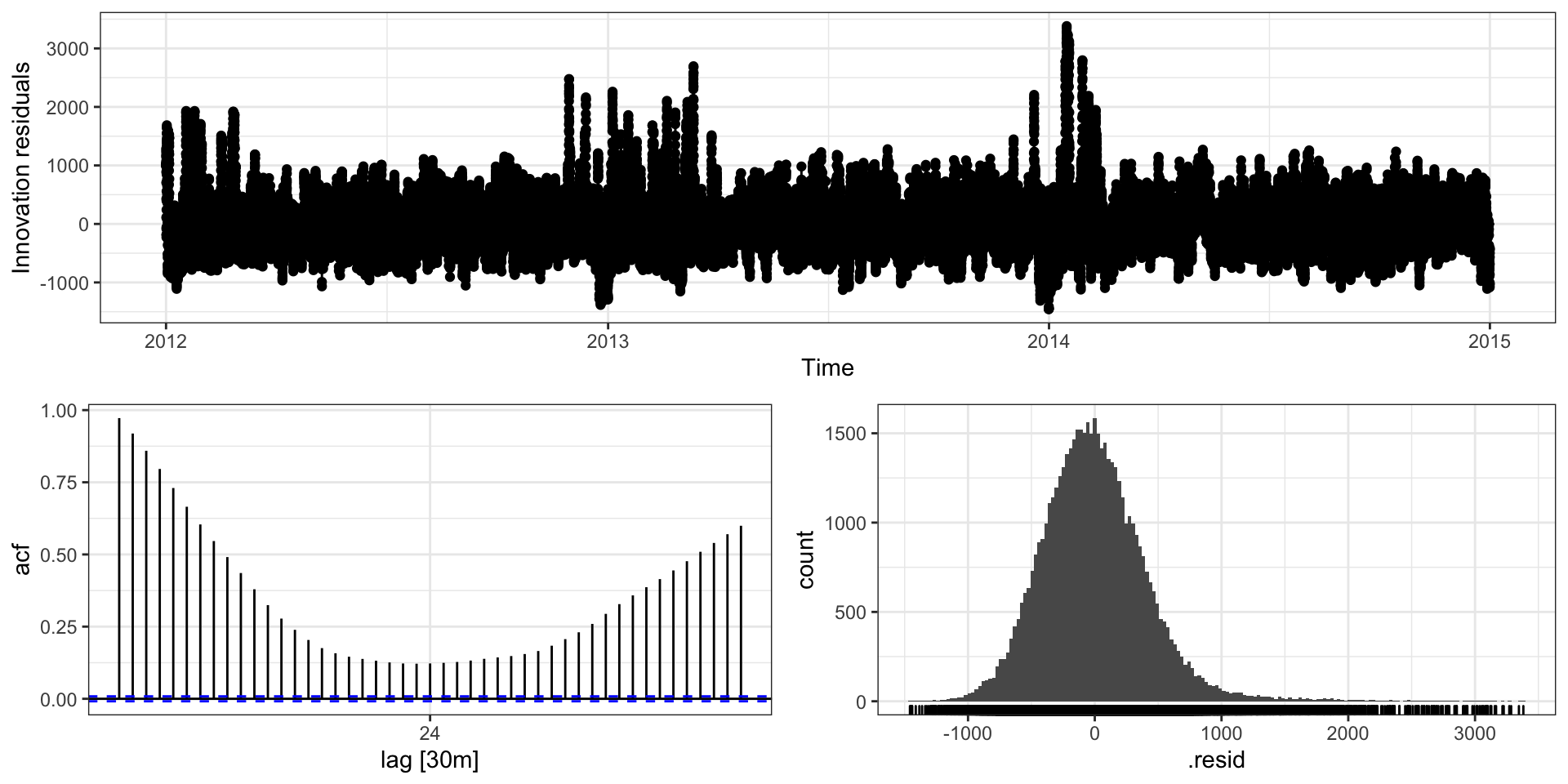
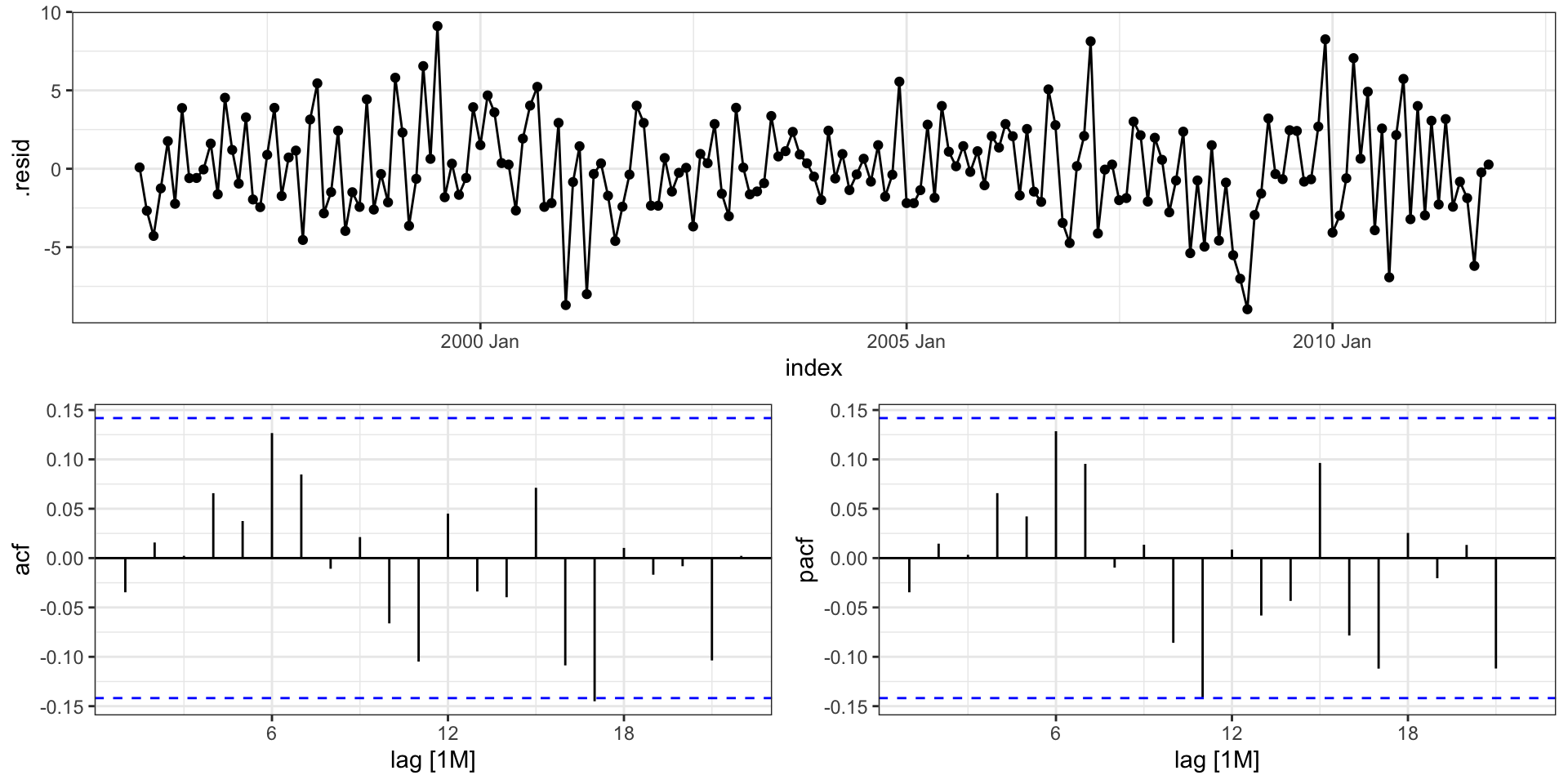
Residuals
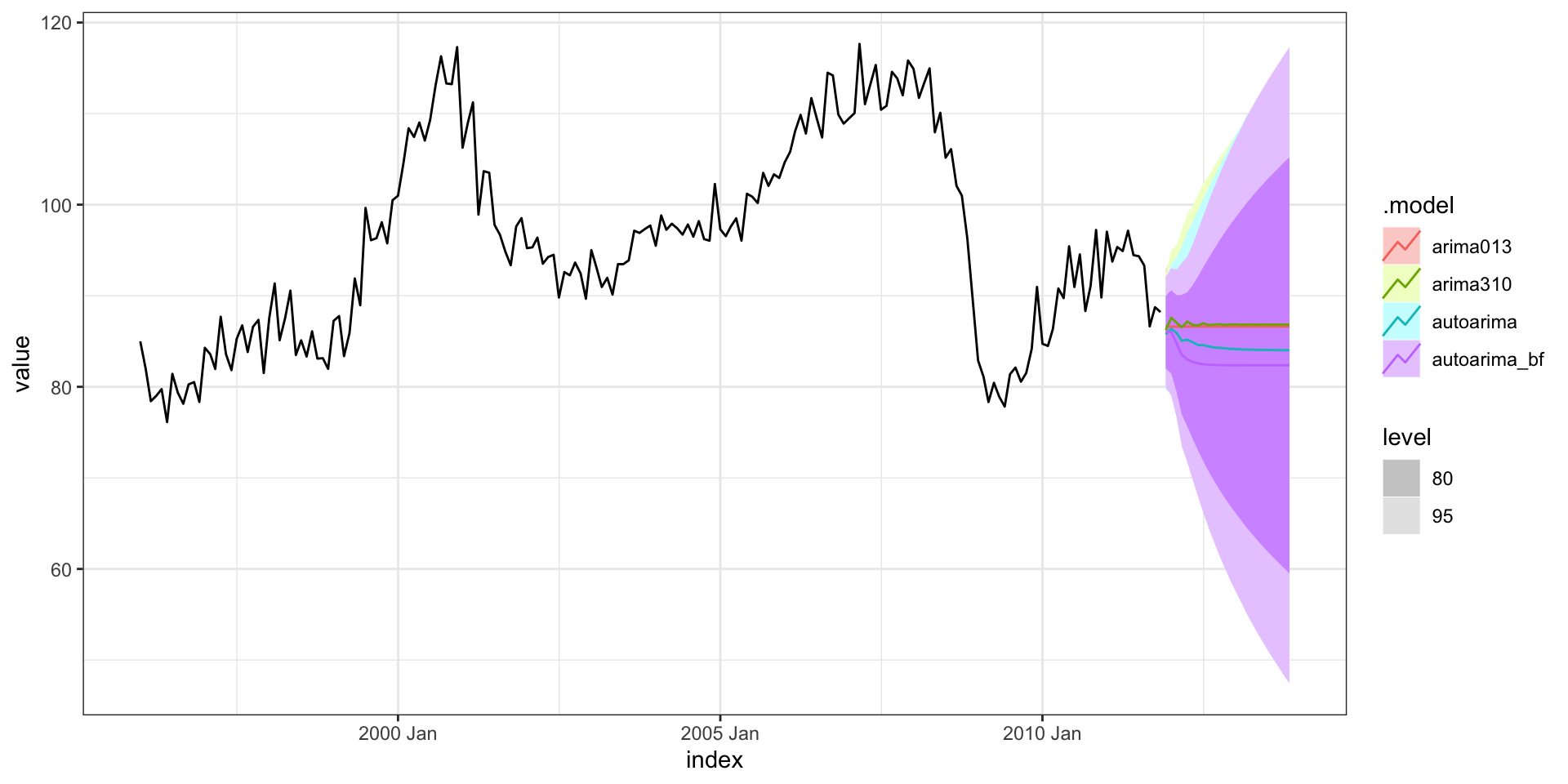
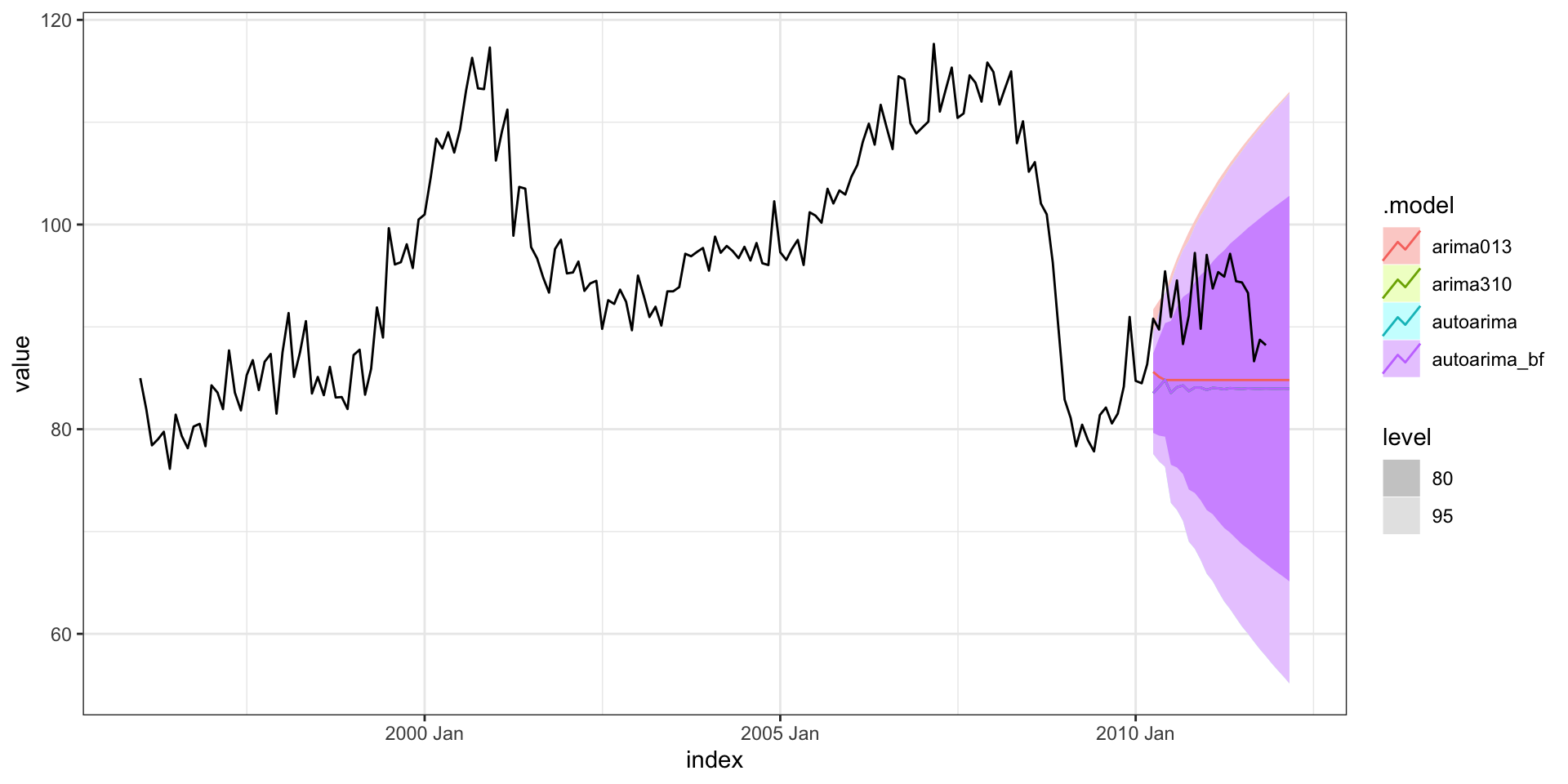
Forecasting - autoplot
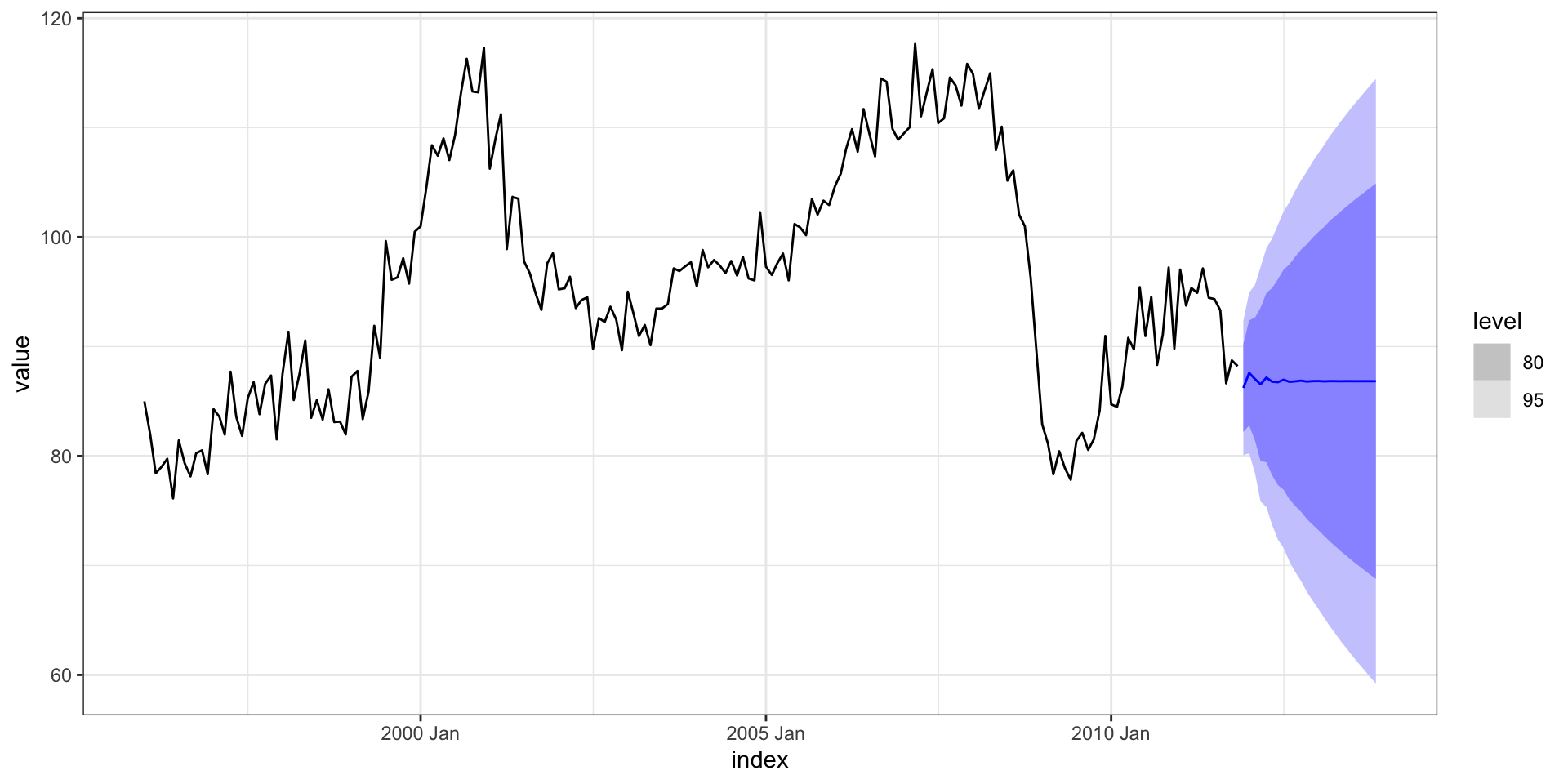
Forecasting - autoplot
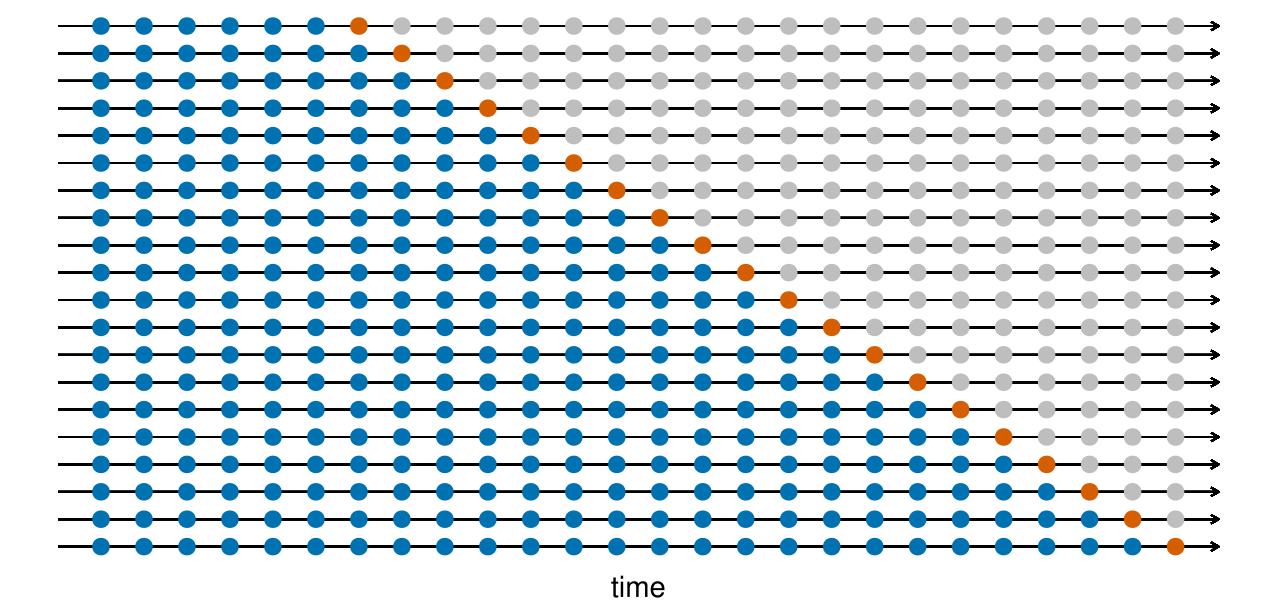
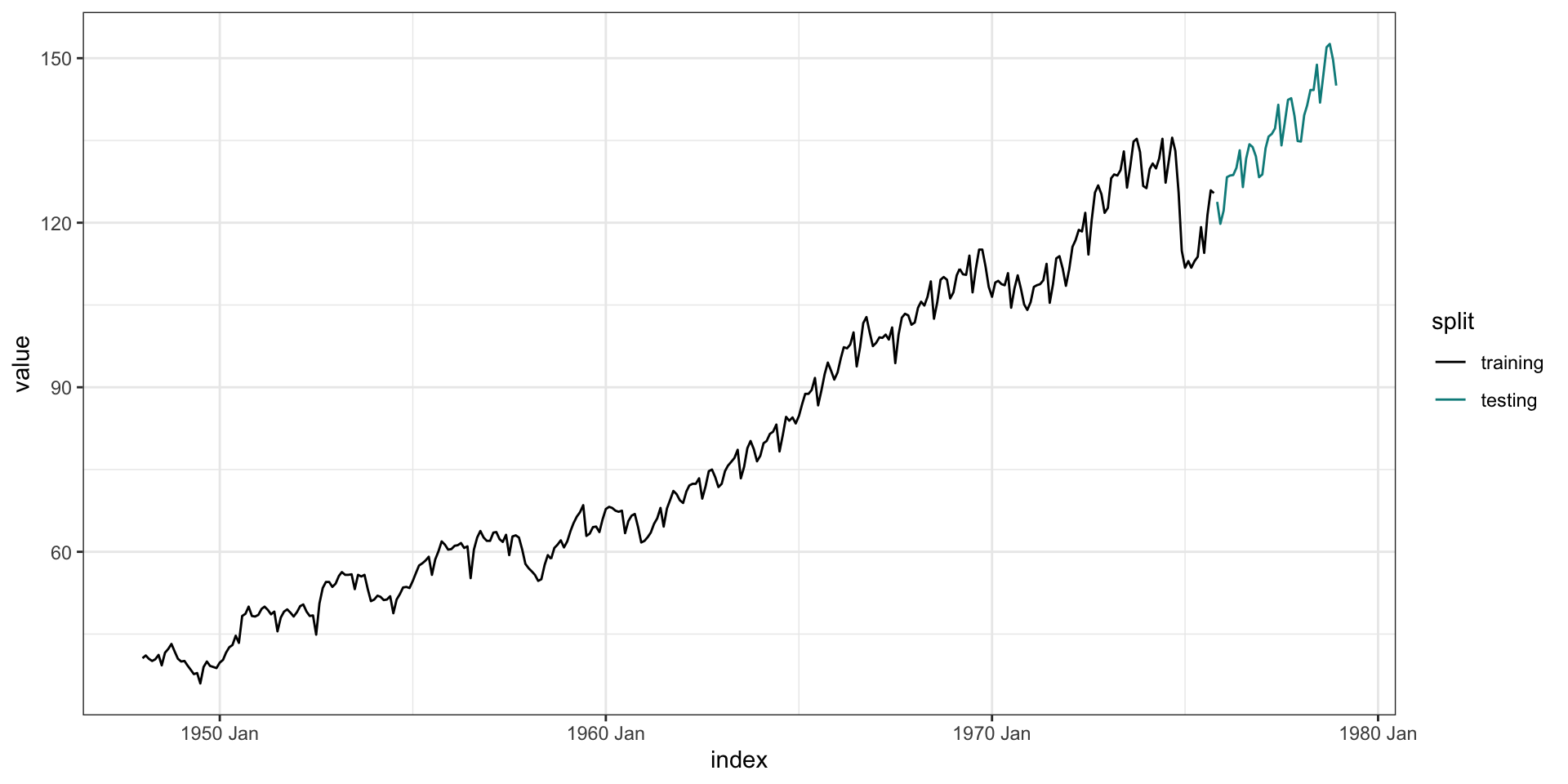
Test train split
The general approach is to keep the data ordered and split the first prop% into the training data and the remainder as testing data.

# A tsibble: 20 x 2 [1M]
index value
<mth> <dbl>
1 2010 Apr 90.8
2 2010 May 89.7
3 2010 Jun 95.4
4 2010 Jul 91.0
5 2010 Aug 94.5
6 2010 Sep 88.3
7 2010 Oct 91.1
8 2010 Nov 97.2
9 2010 Dec 89.8
10 2011 Jan 97.0
11 2011 Feb 93.7
12 2011 Mar 95.4
13 2011 Apr 94.9
14 2011 May 97.1
15 2011 Jun 94.5
16 2011 Jul 94.3
17 2011 Aug 93.3
18 2011 Sep 86.6
19 2011 Oct 88.7
20 2011 Nov 88.2Forecasting
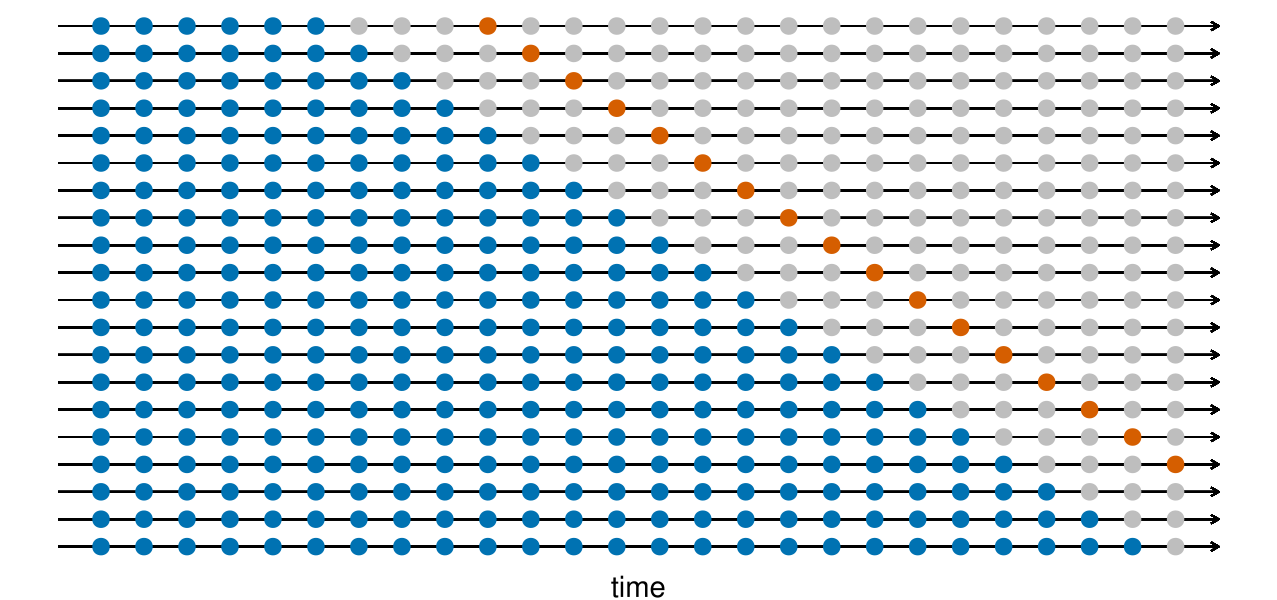
Rolling forecasting origin
One-step ahead predictive performance
Four-step ahead predictive performance
prodn from astsa
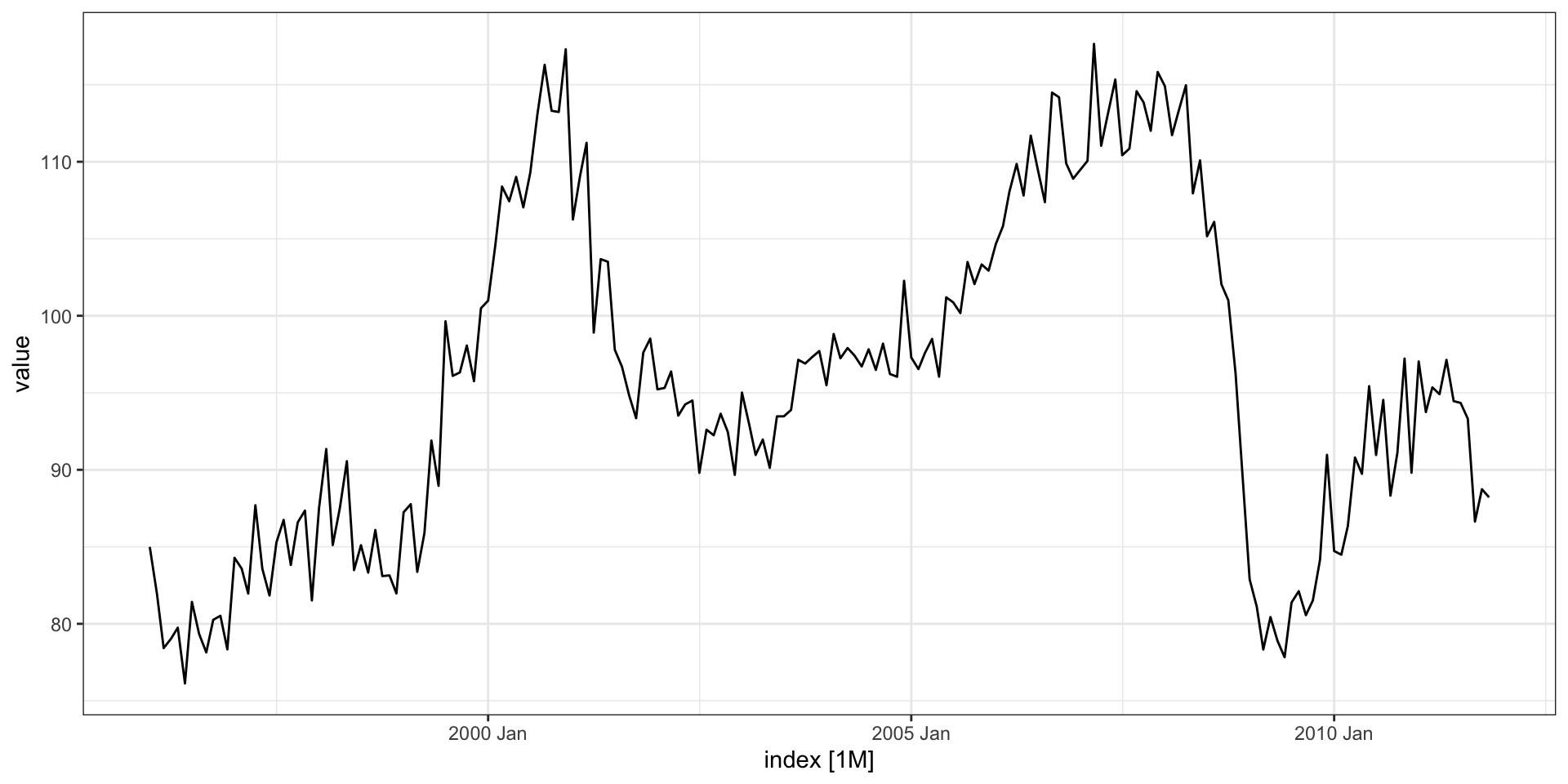
Monthly Federal Reserve Board Production Index (1948-1978)
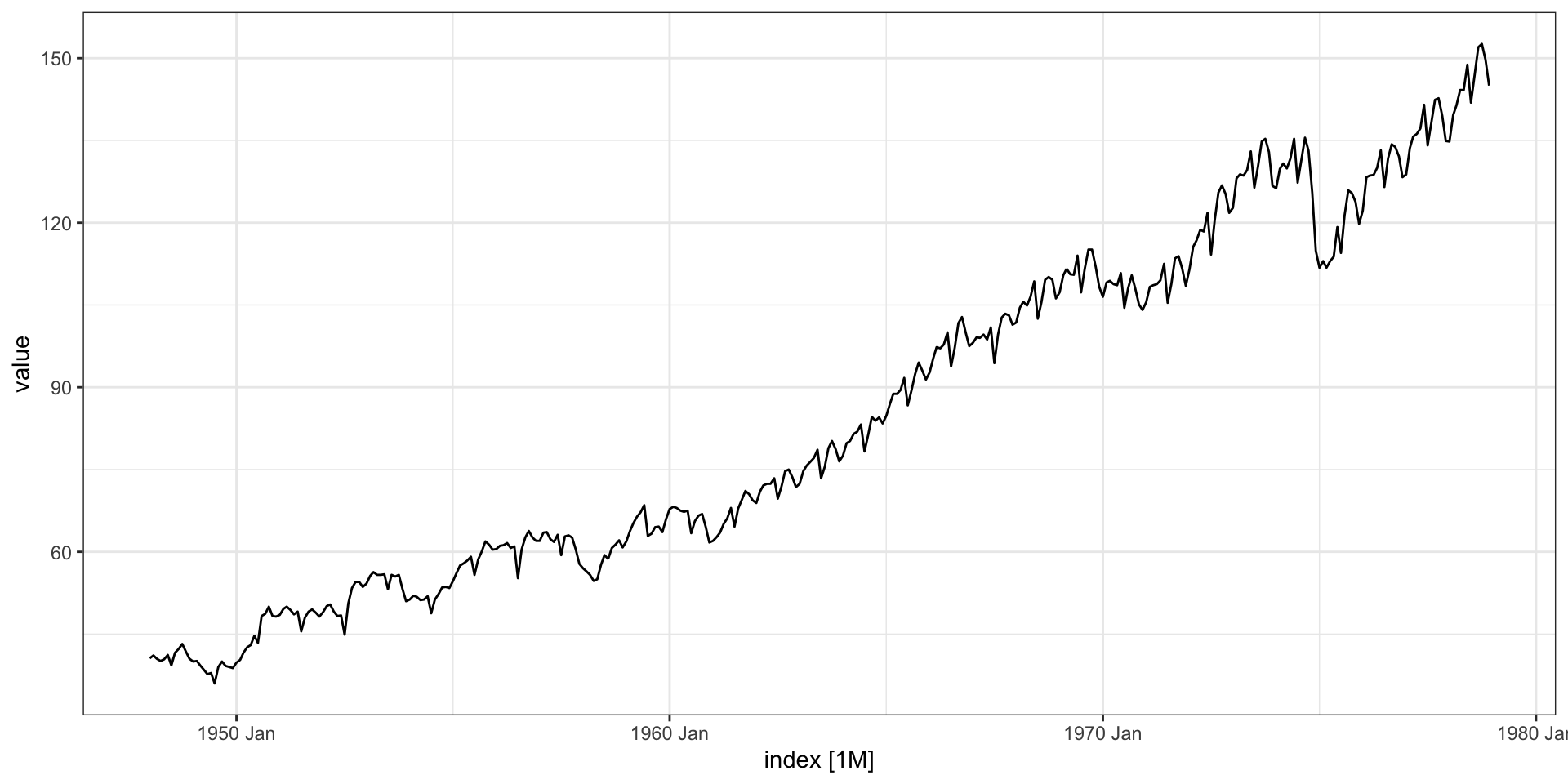
Test train split
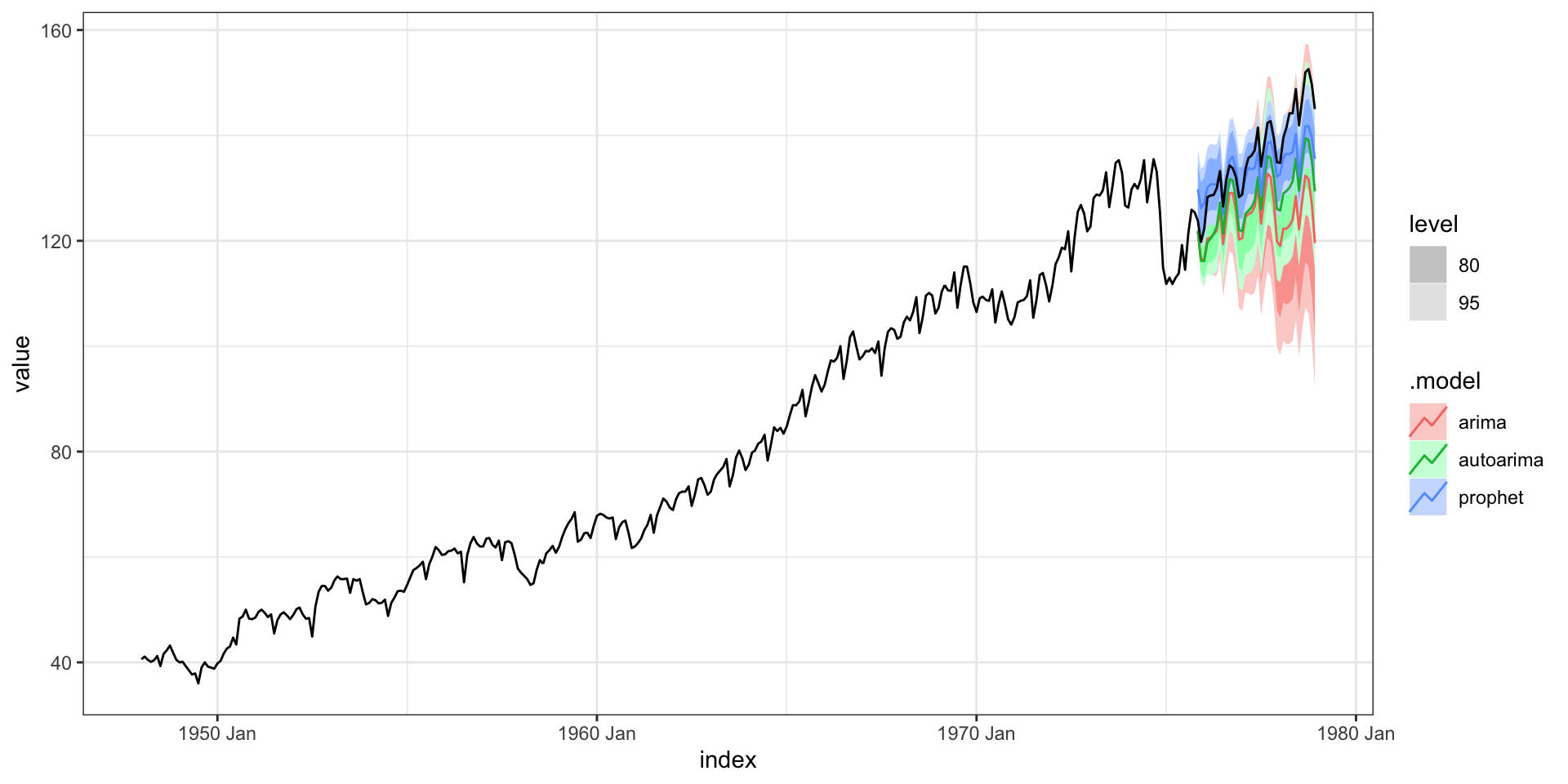
Forecast
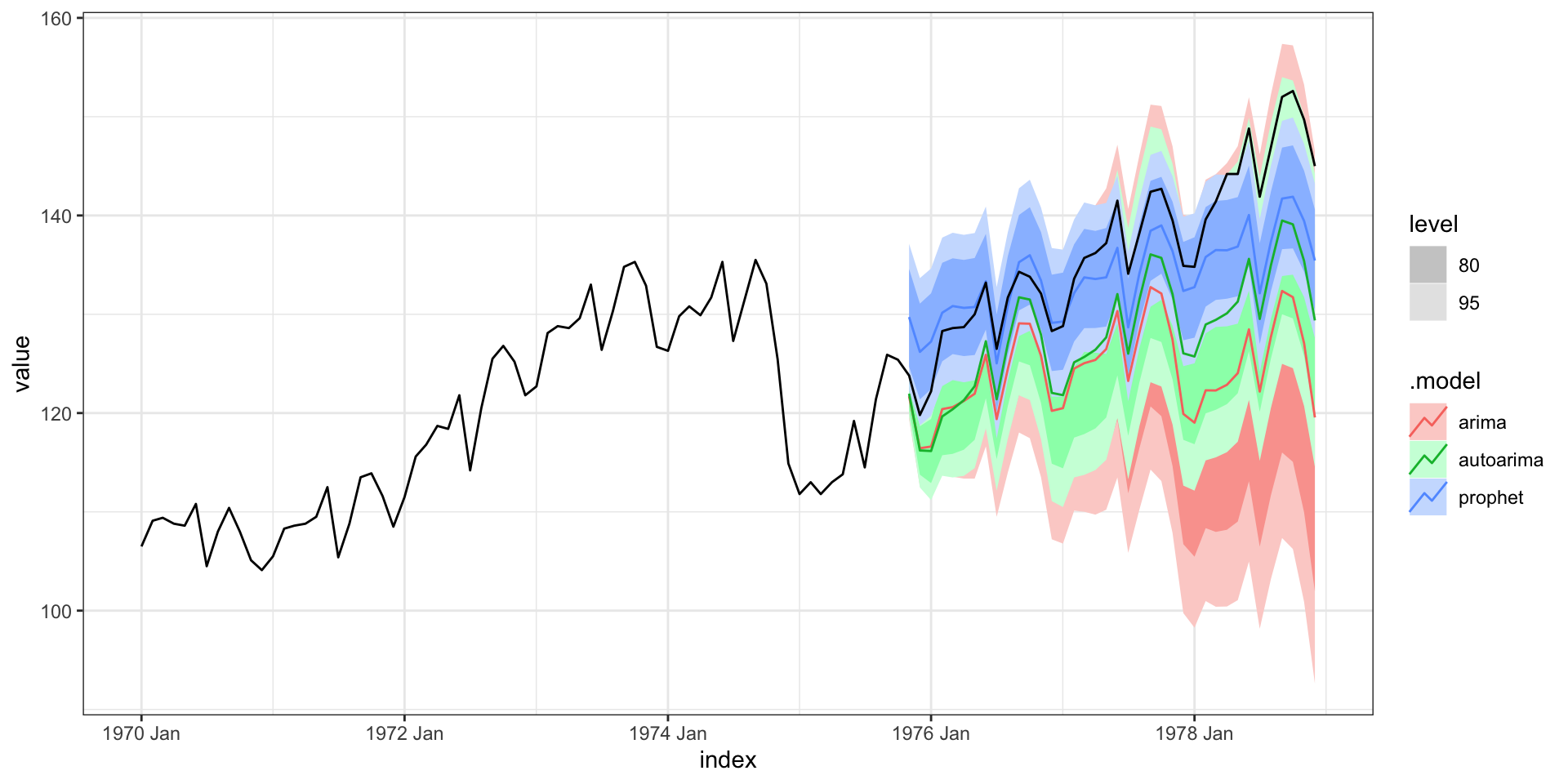
Forecast - zoom
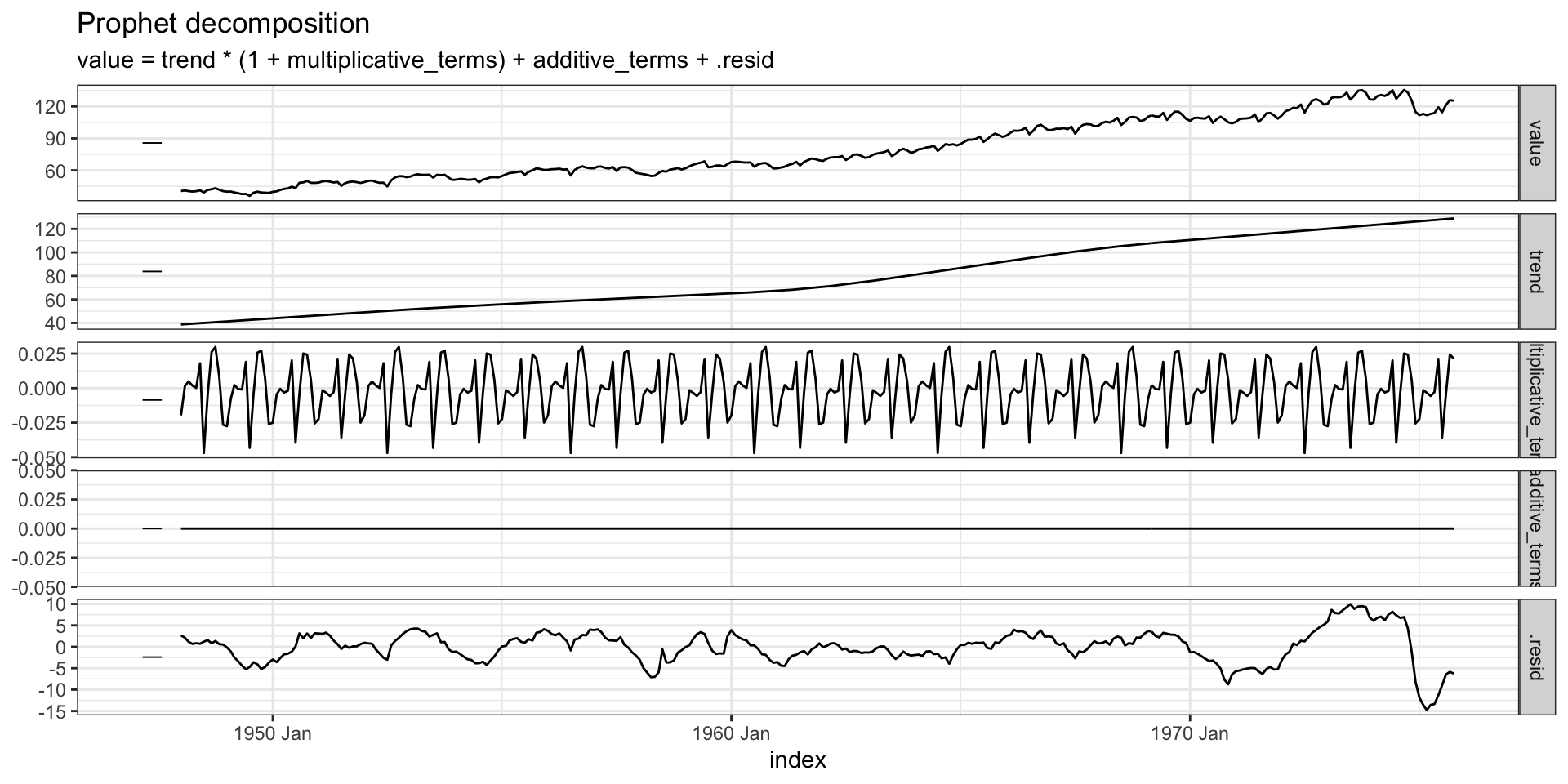
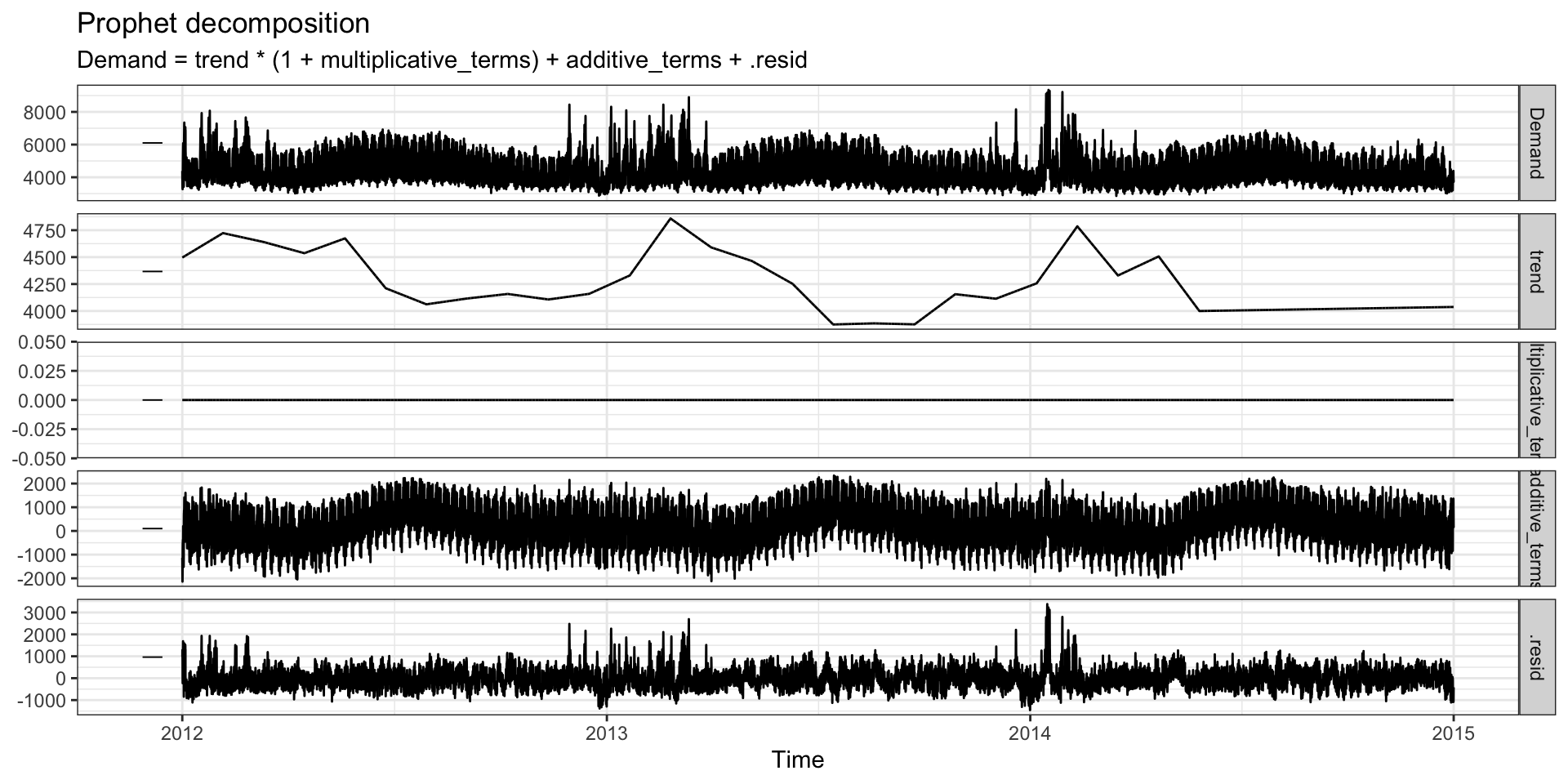
Components
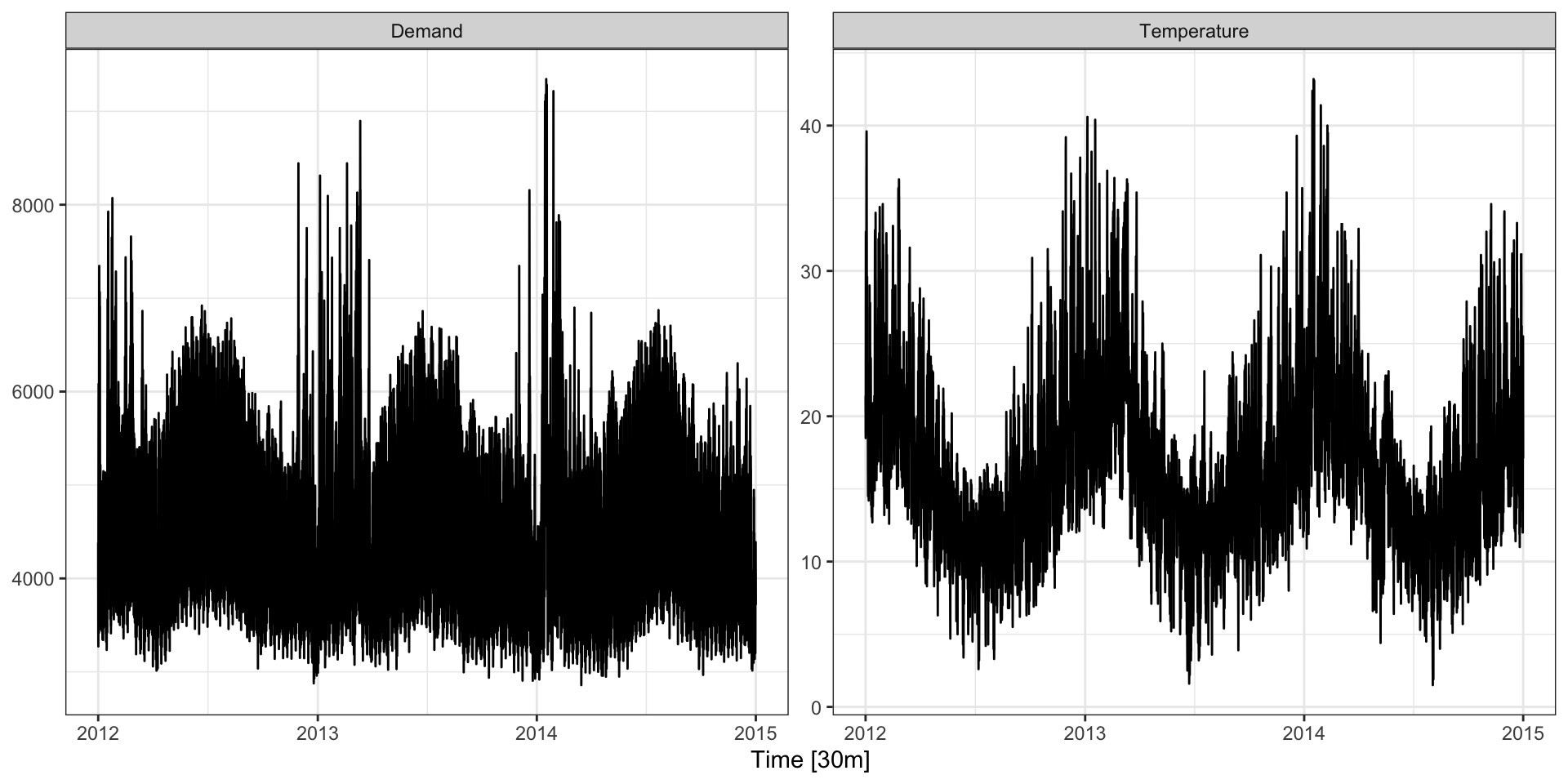
Full data
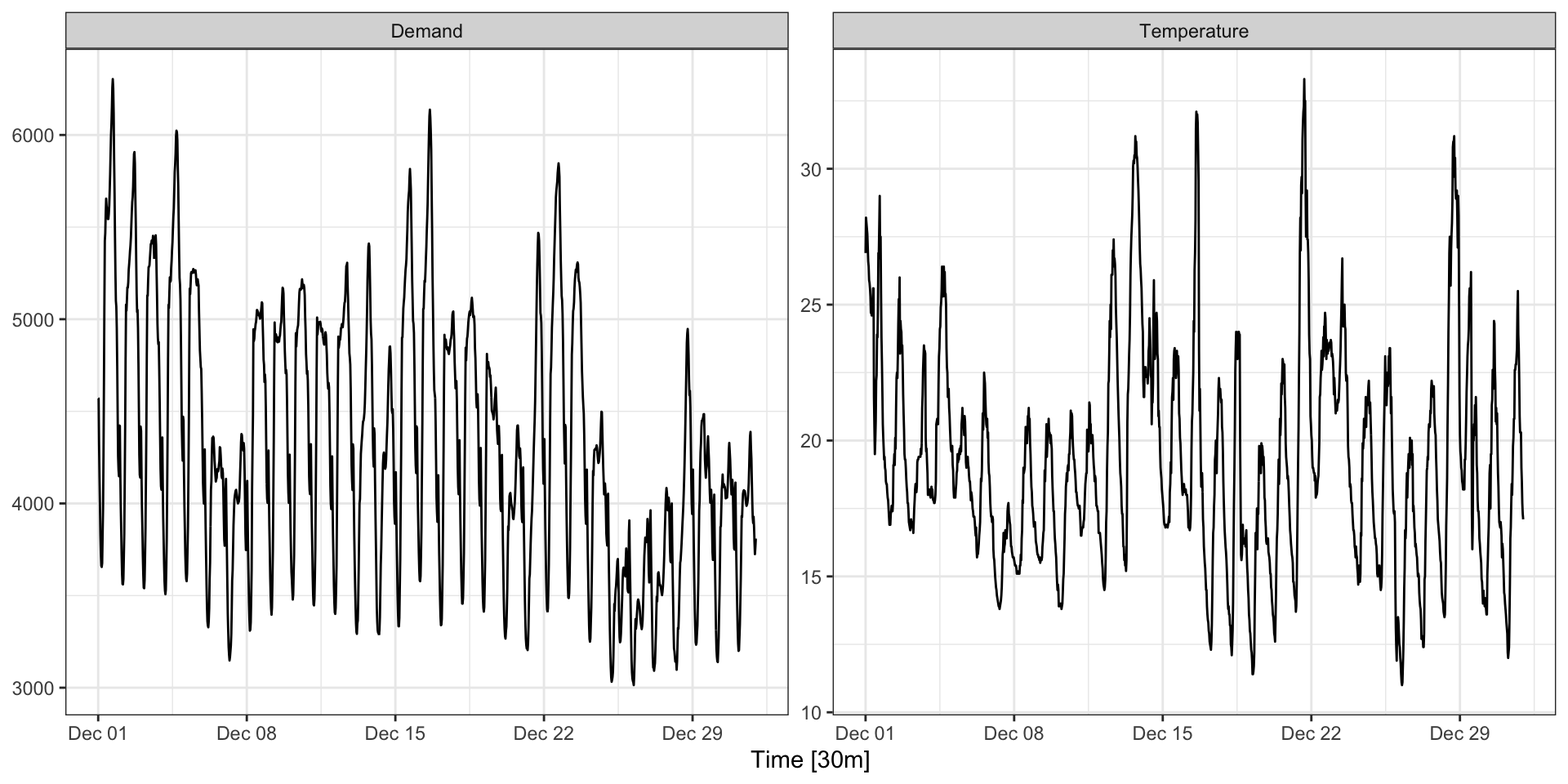
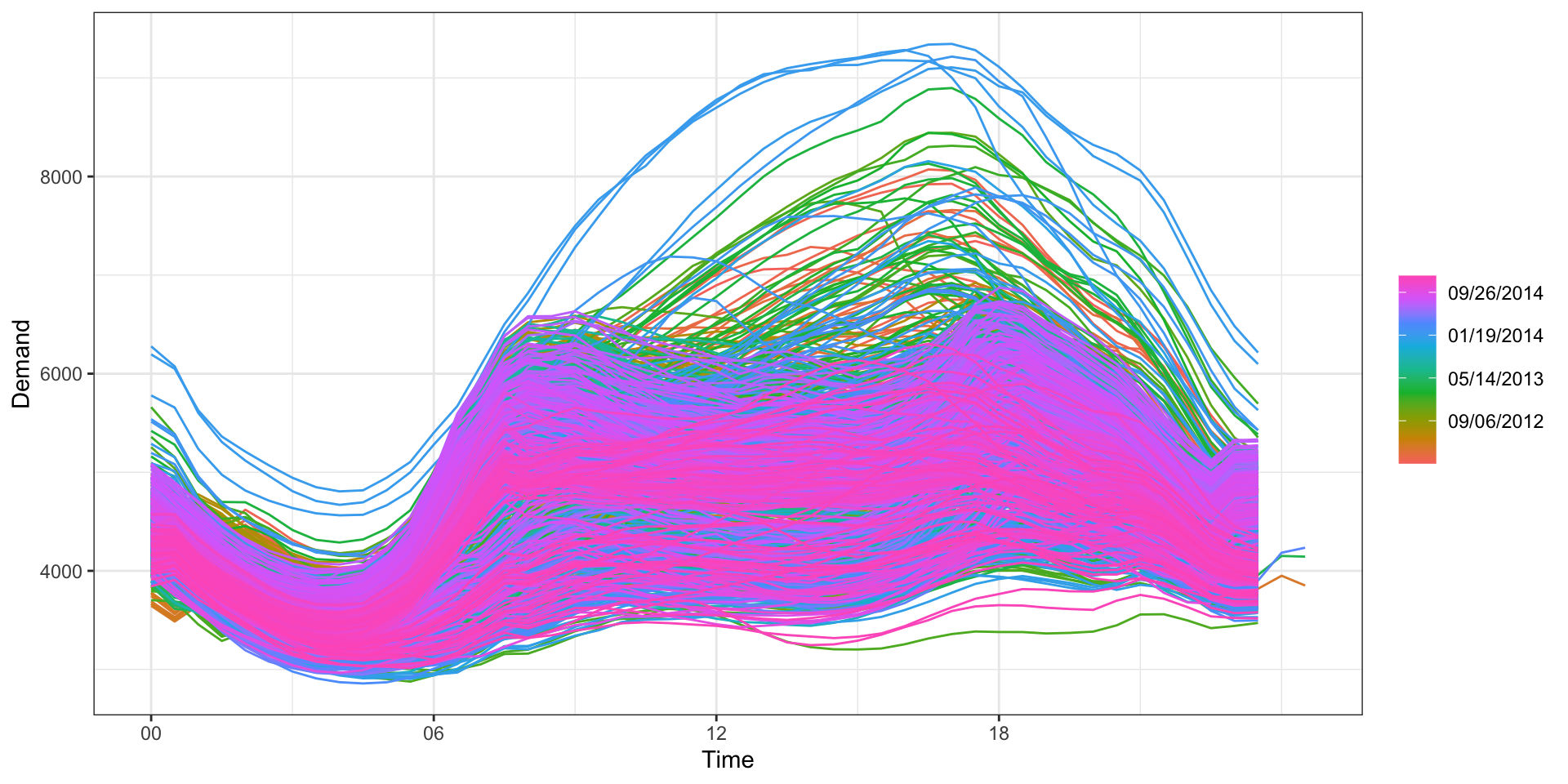
Data - December 2014
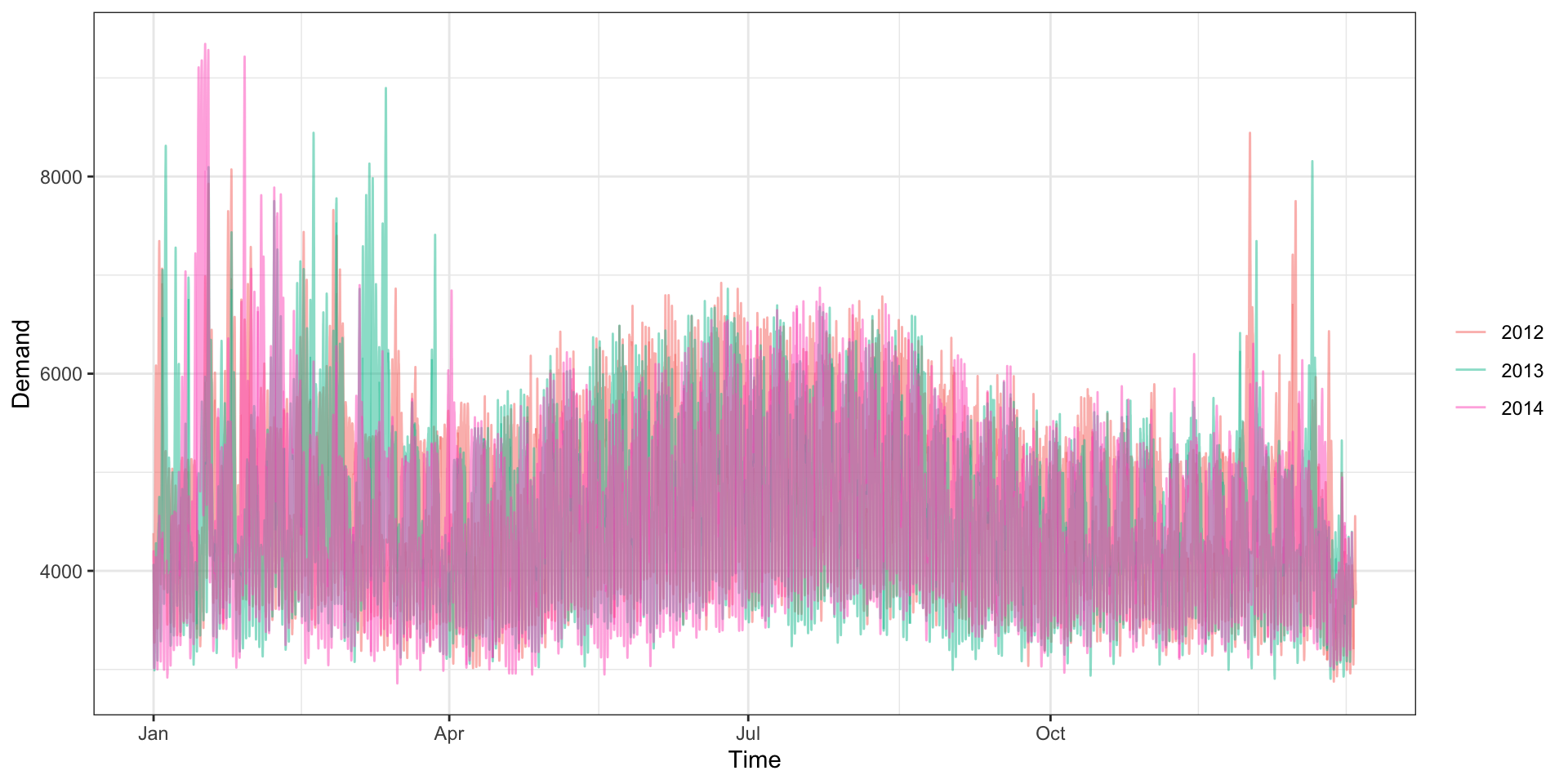
Seasonality - Yearly
Seasonality - Weekly
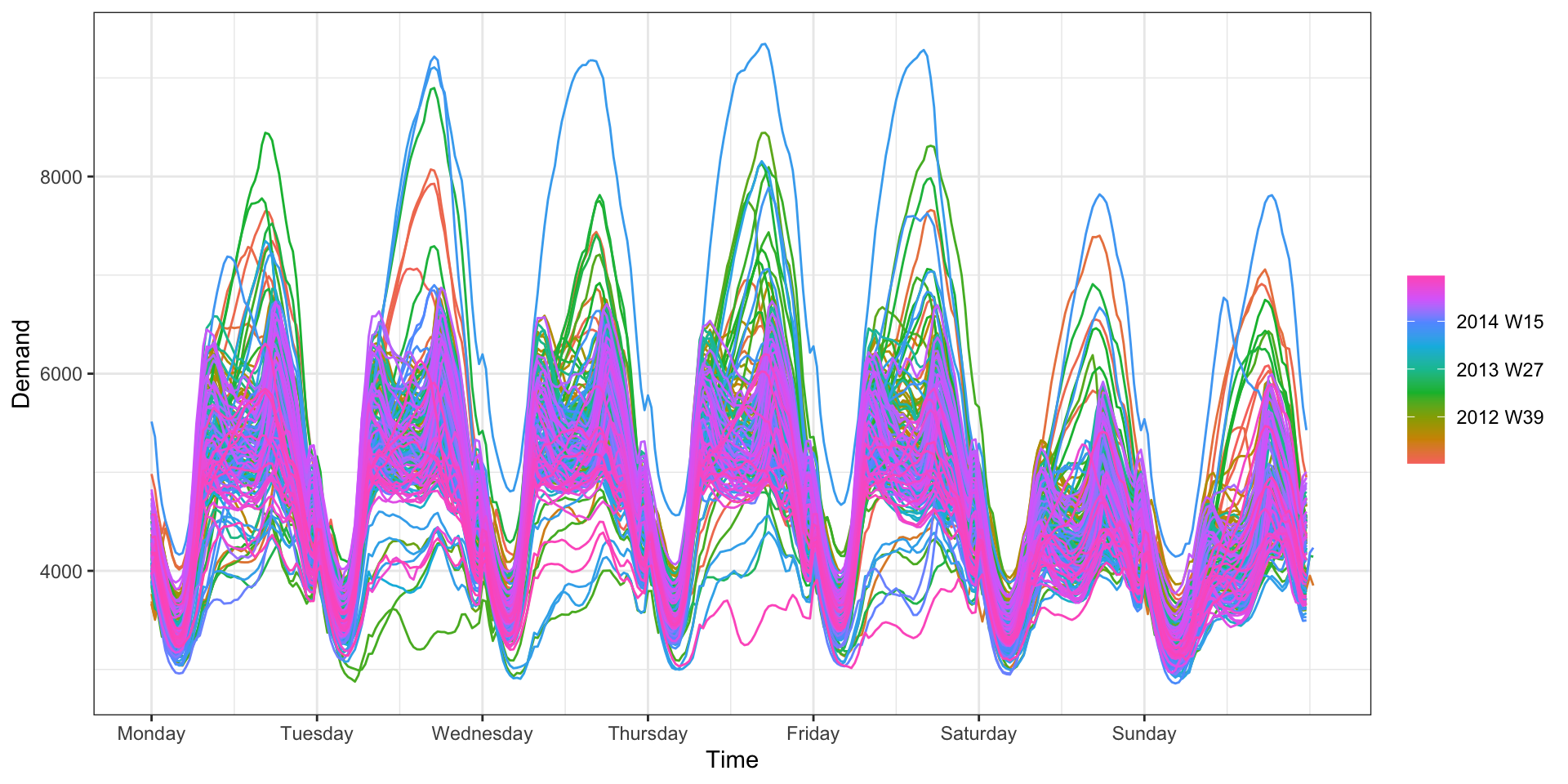
Seasonality - Daily
Components
Residuals