Logistic Regression and Residual Analysis
Lecture 05
Last time
Model Fit
Residuals
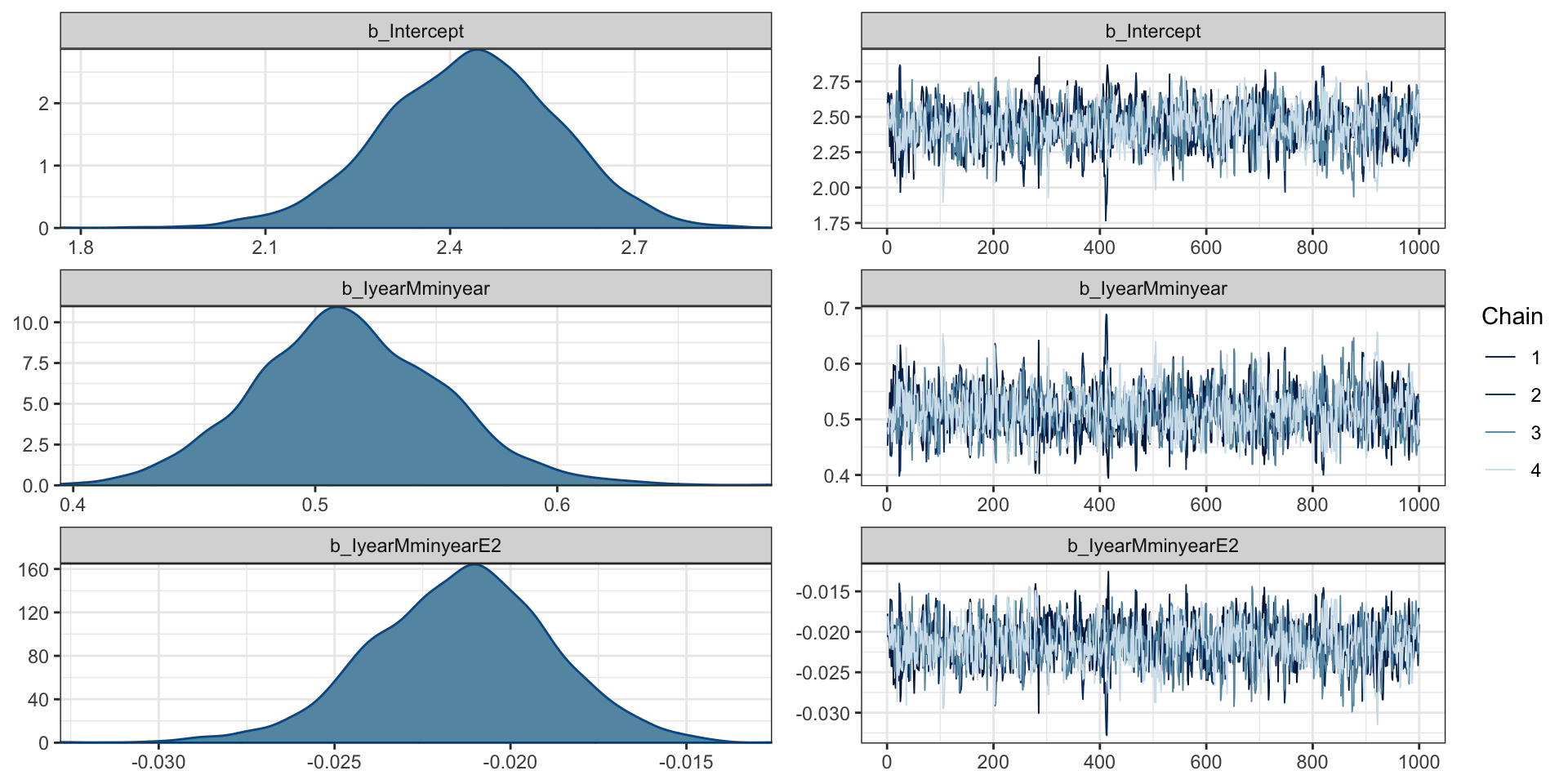
MCMC Diagnostics
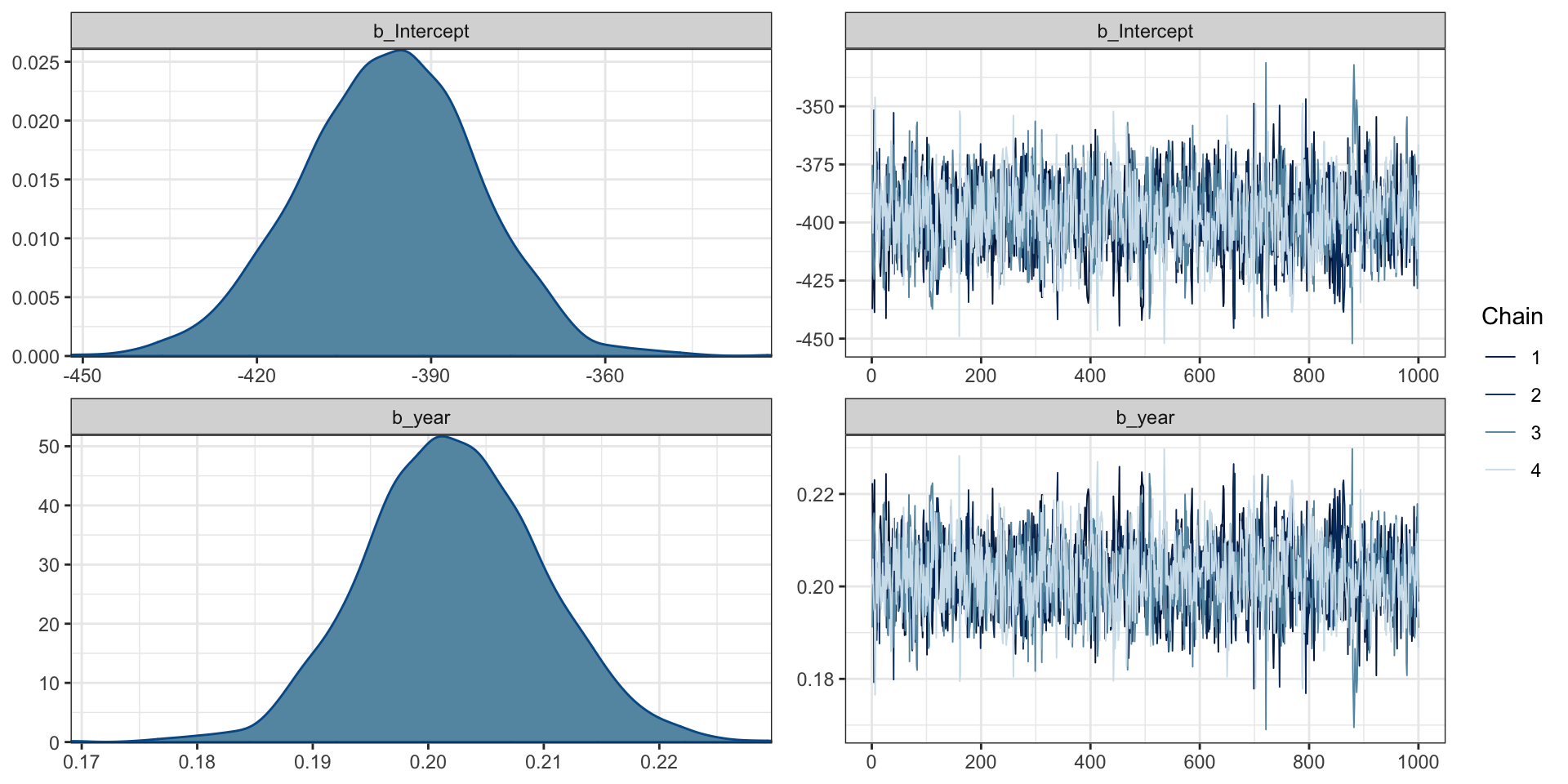
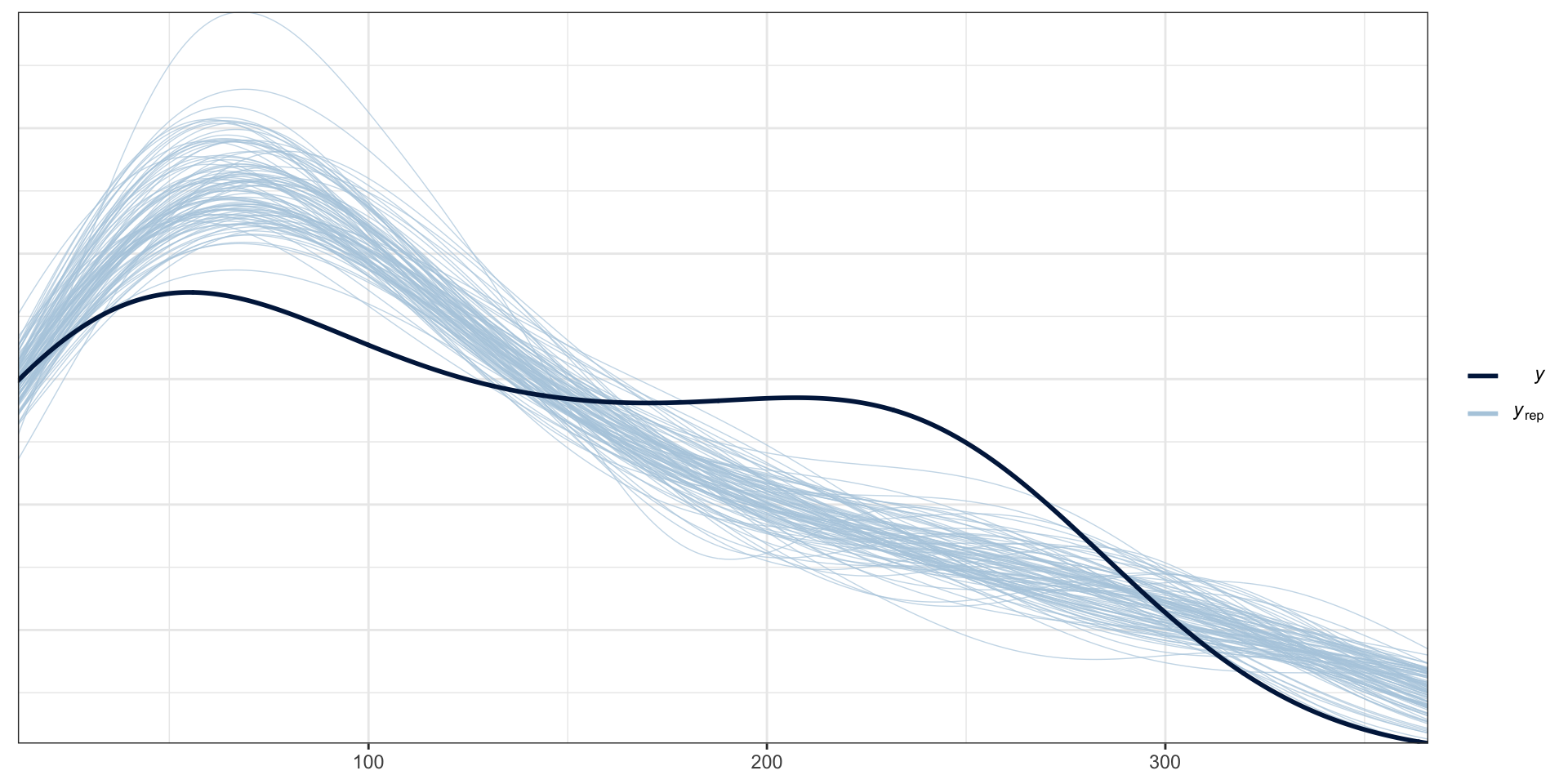
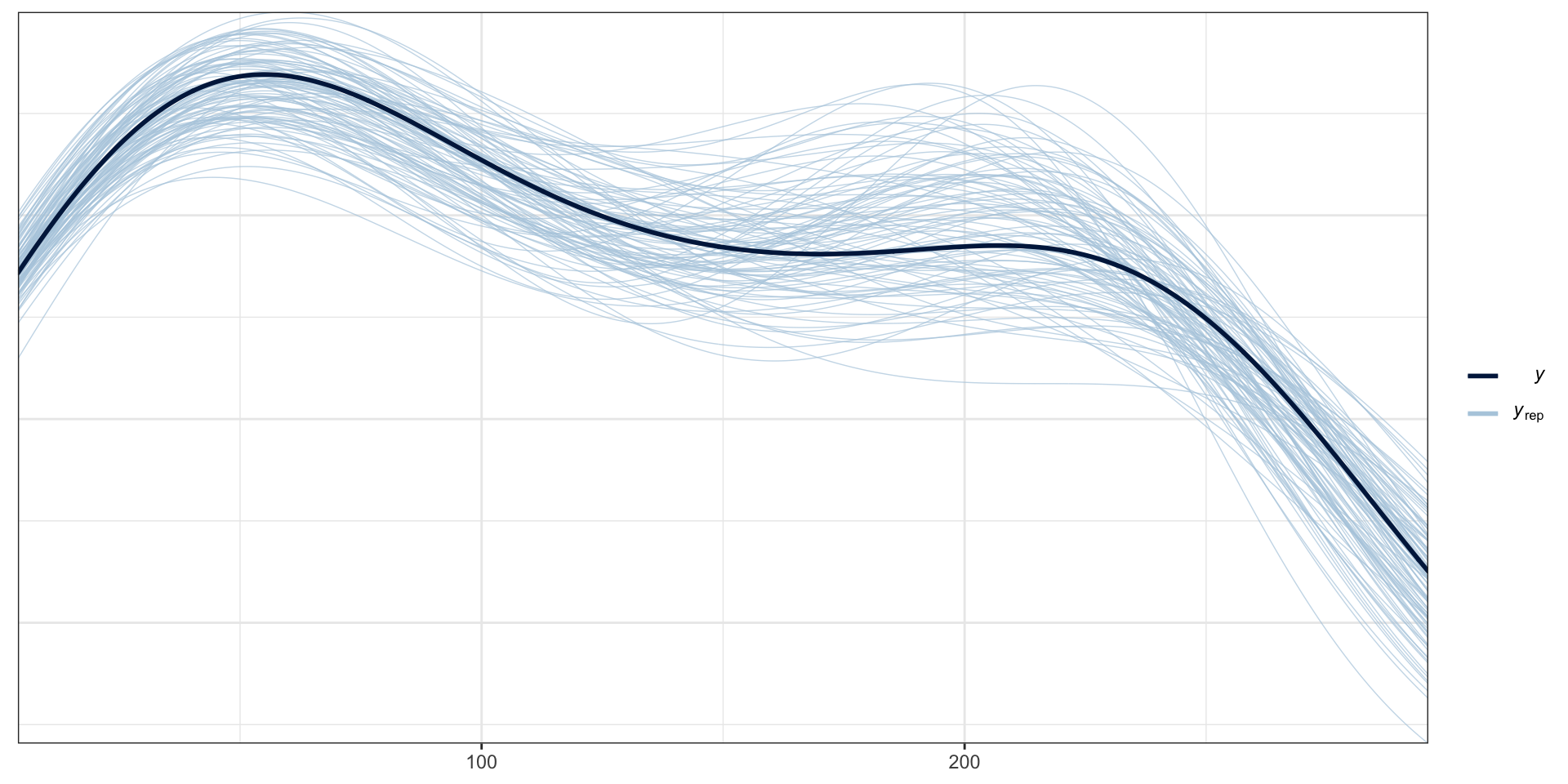
Posterior Predictive Check
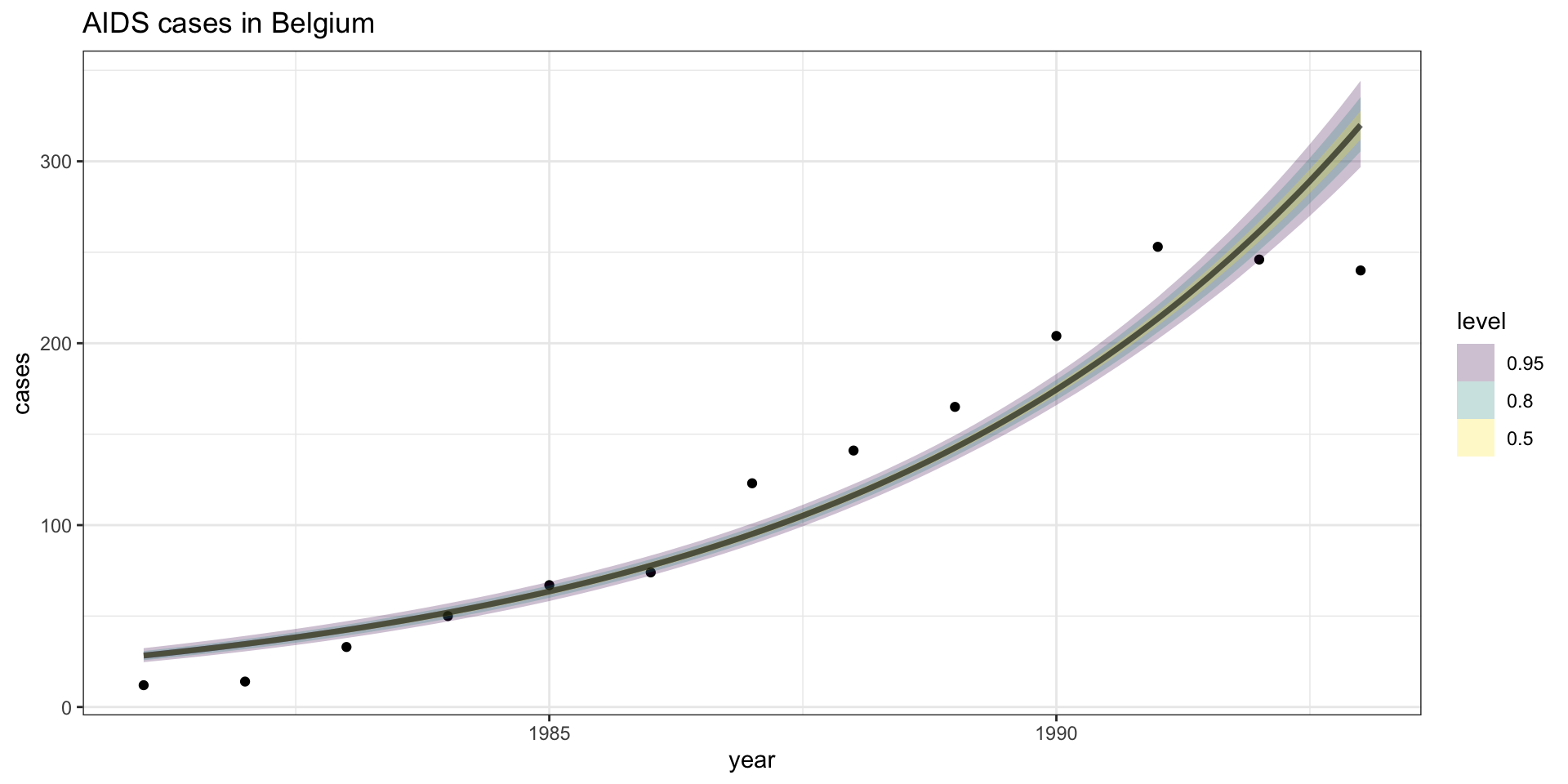
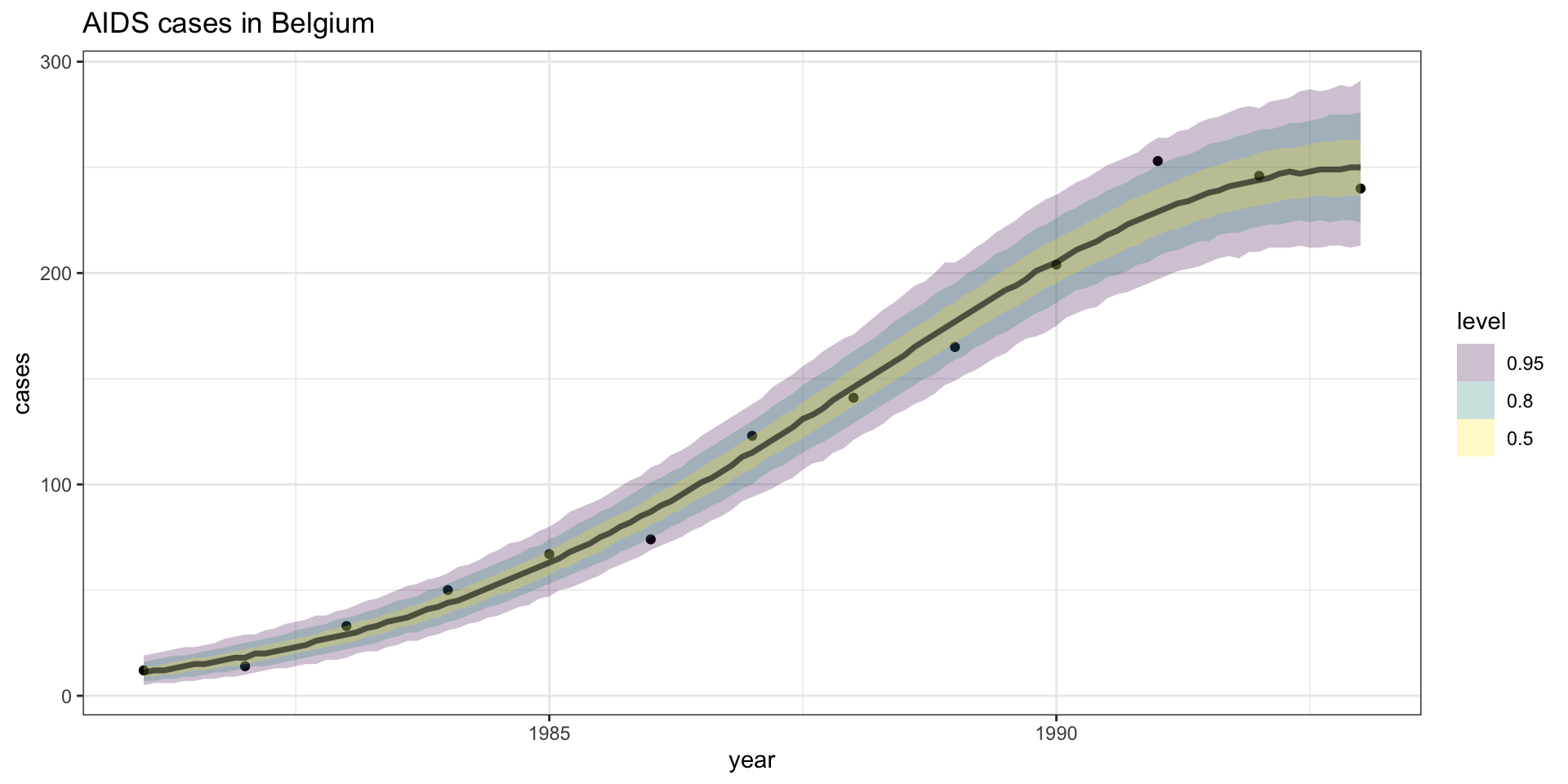
Model fit - \(\lambda\) CI
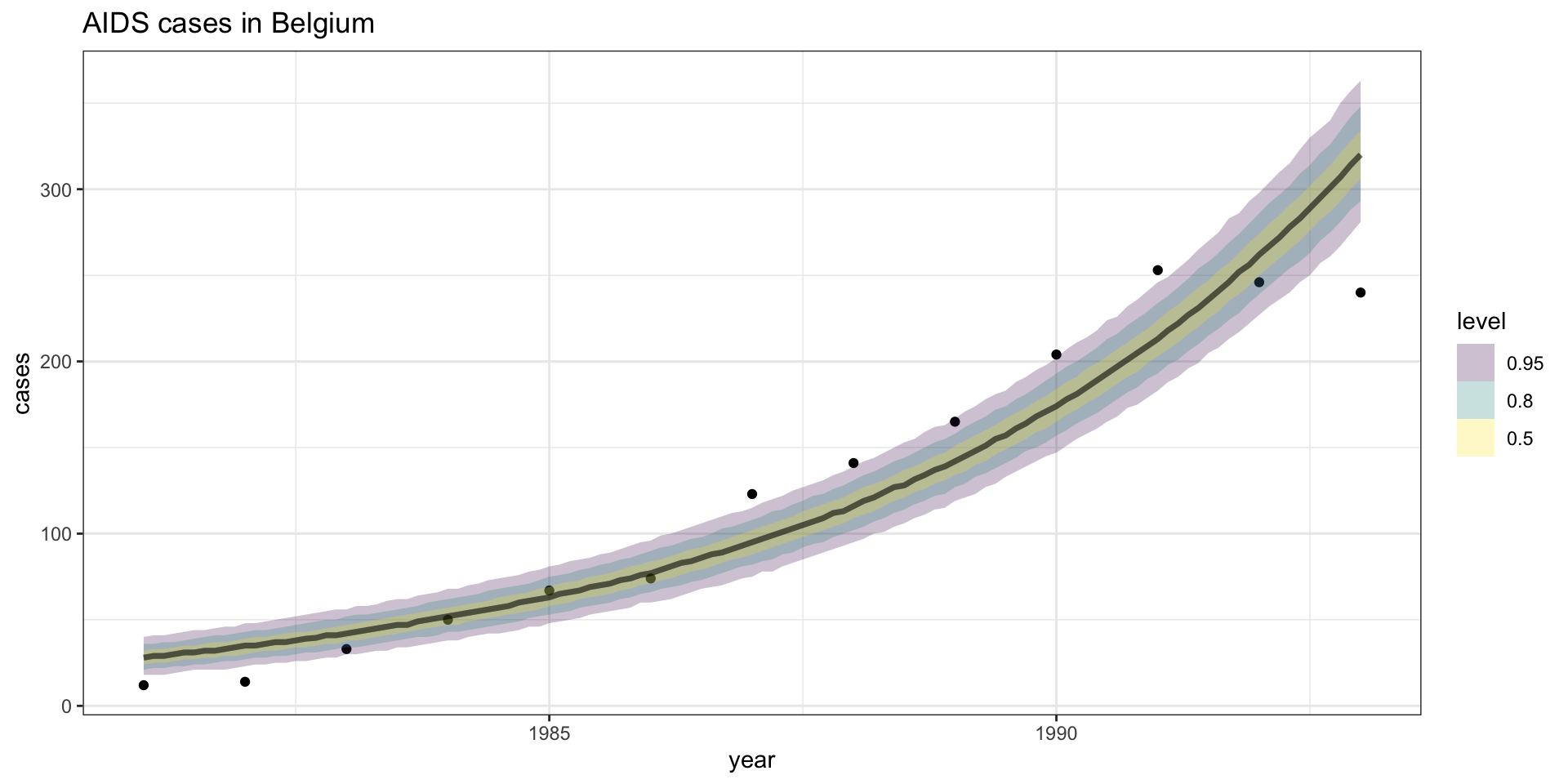
Model fit - \(Y\) CI
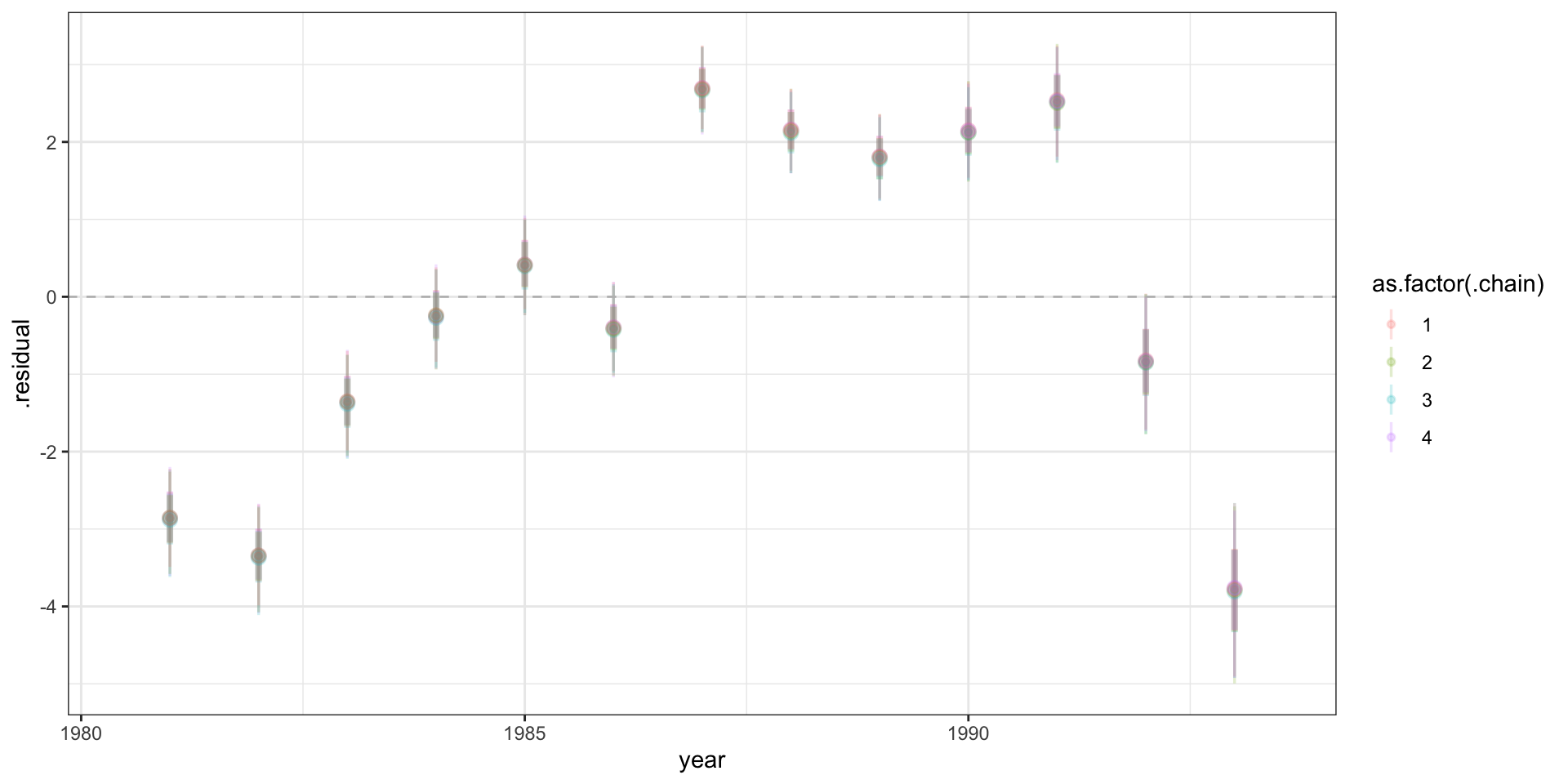
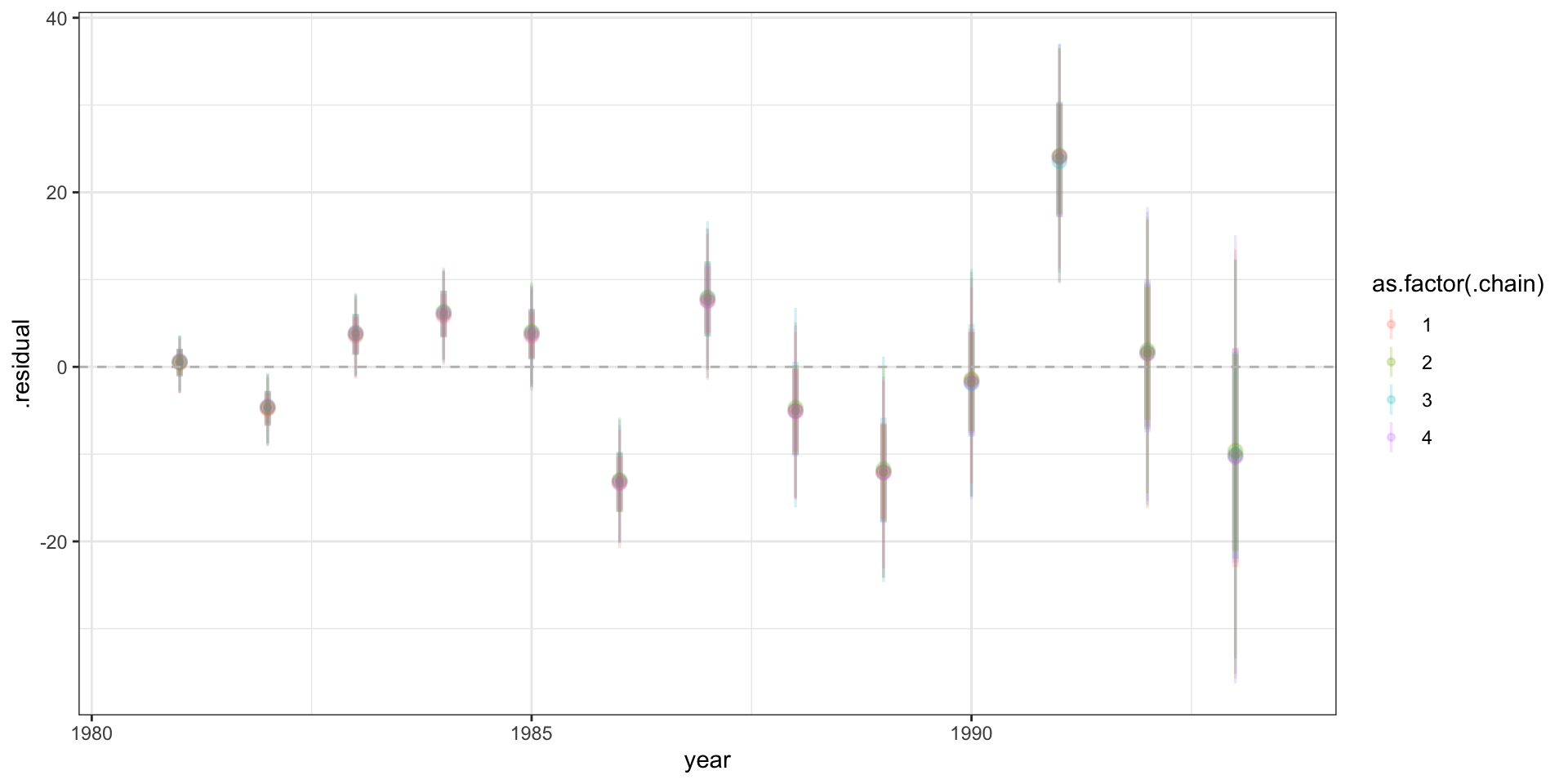
Residual plot
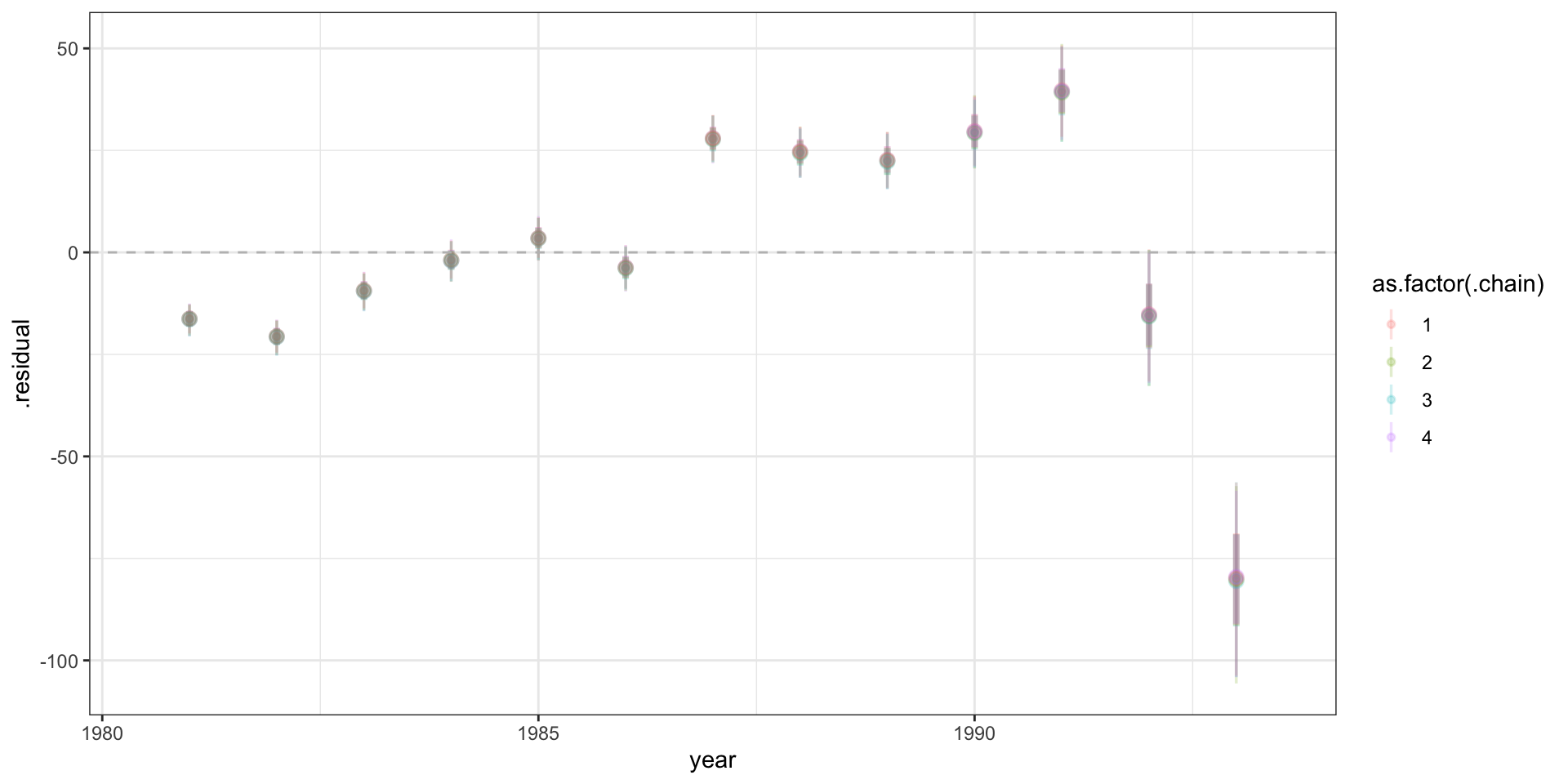
Standardized residuals?
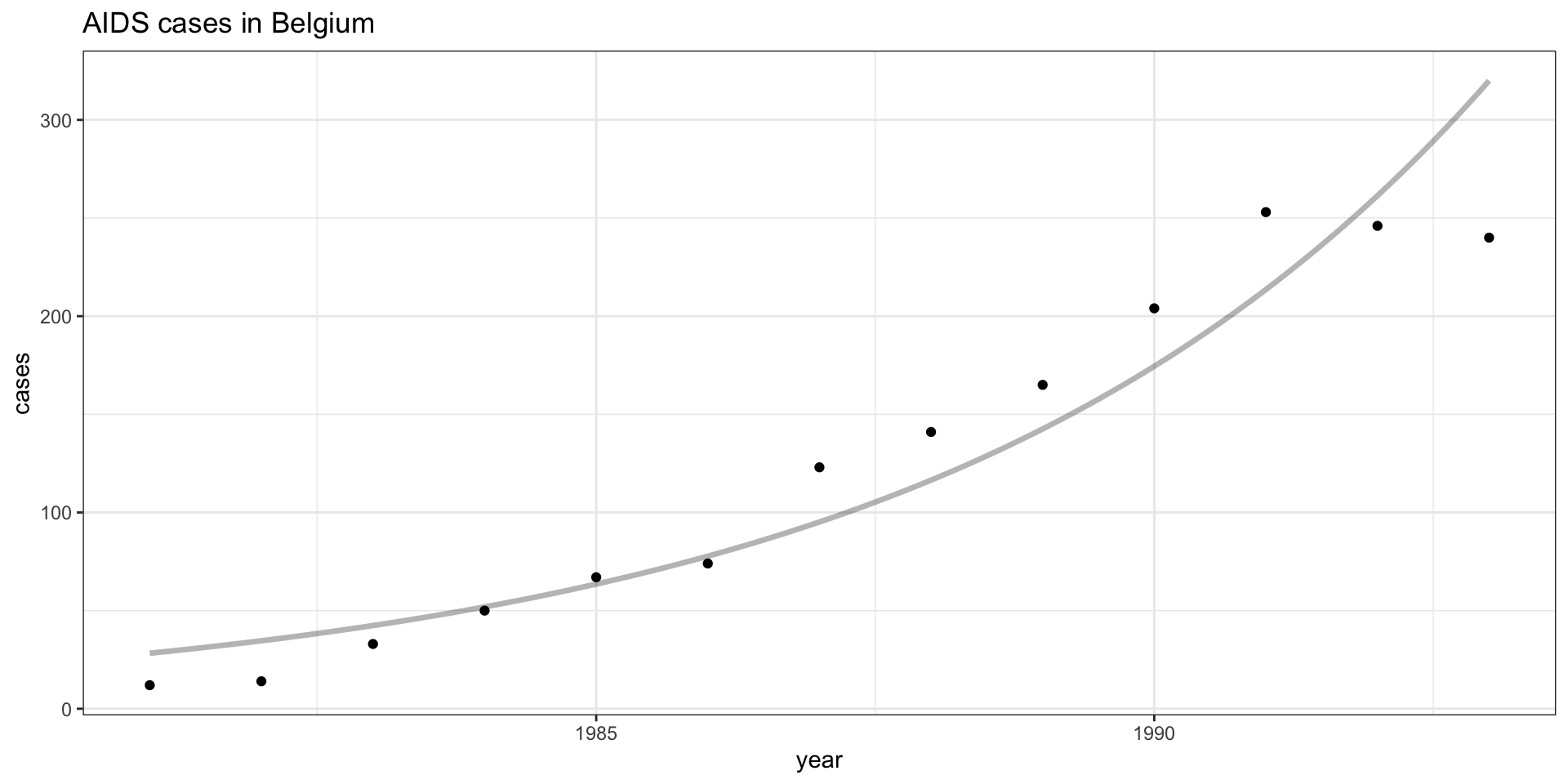
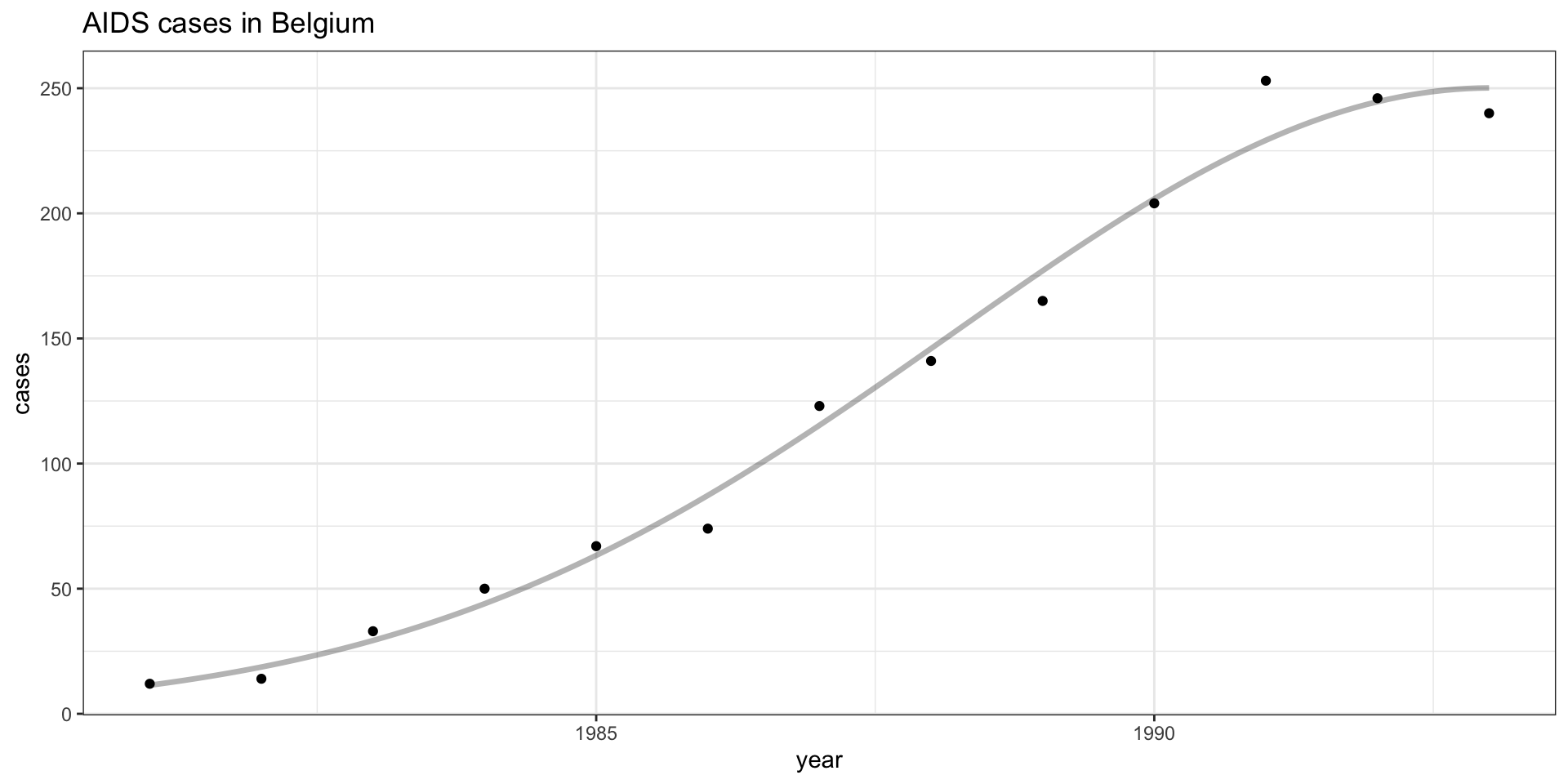
Quadratic fit
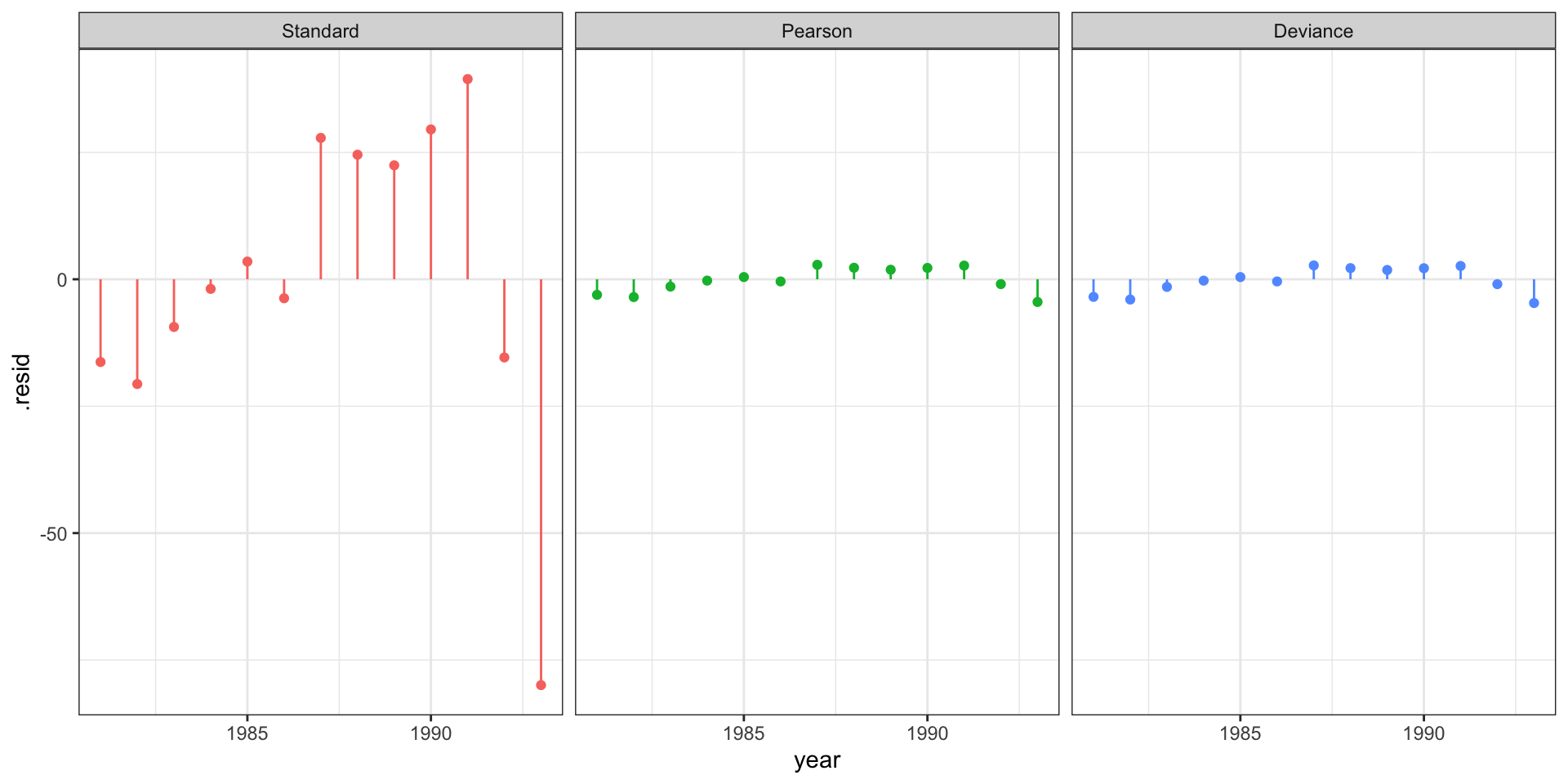
Quadratic fit - residuals
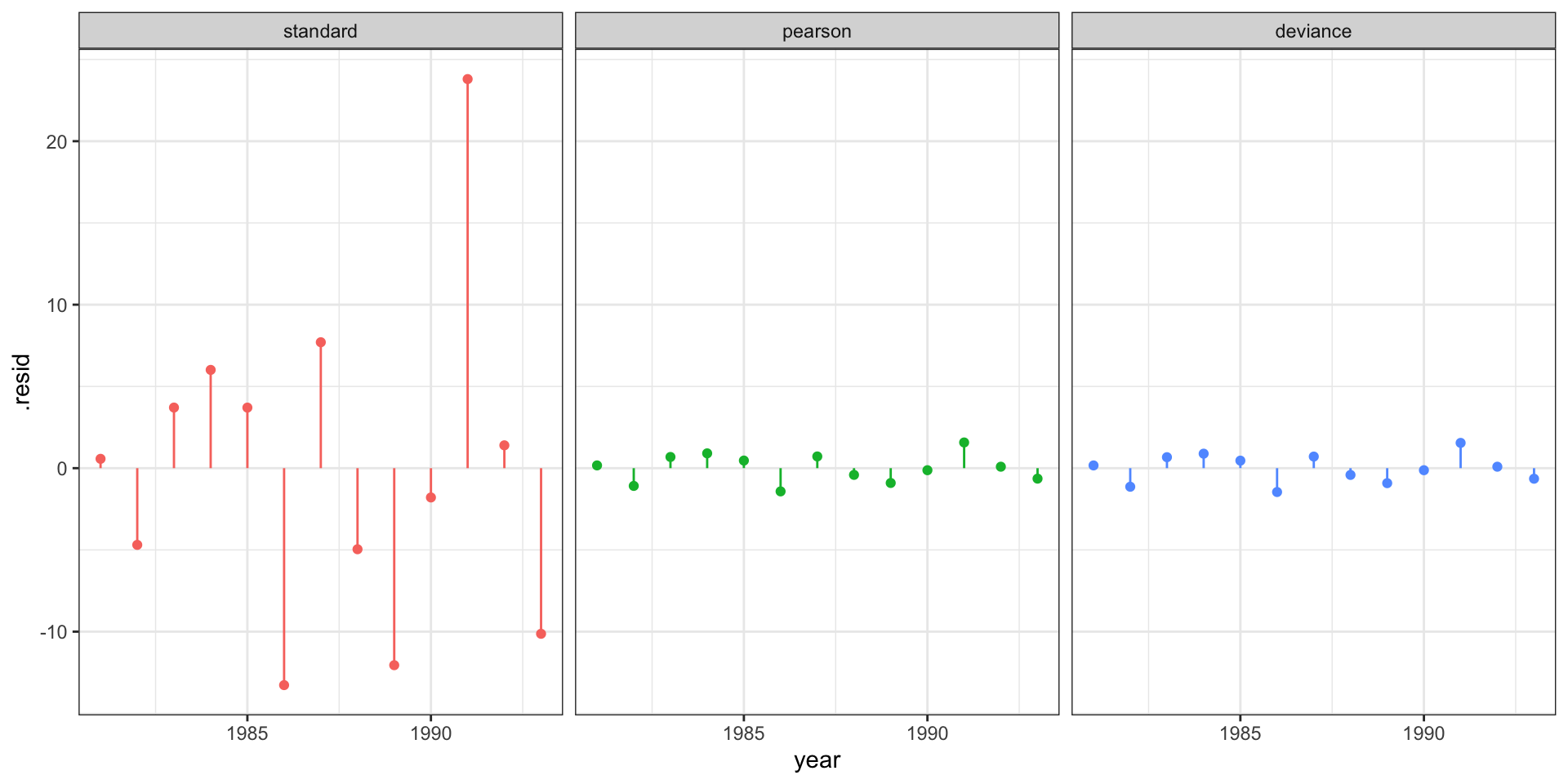
Diagnostics
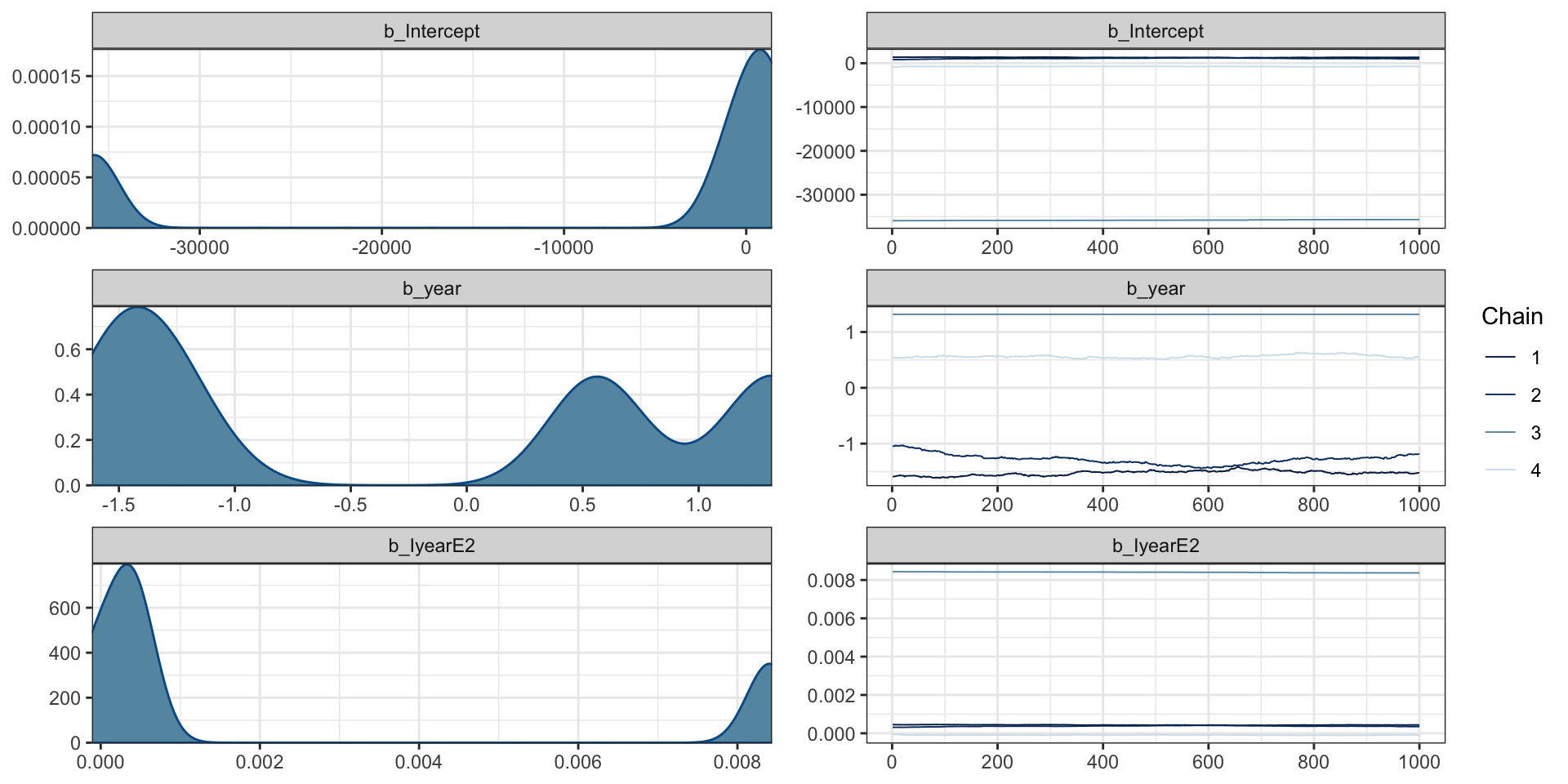
Diagnostics
PP Checks
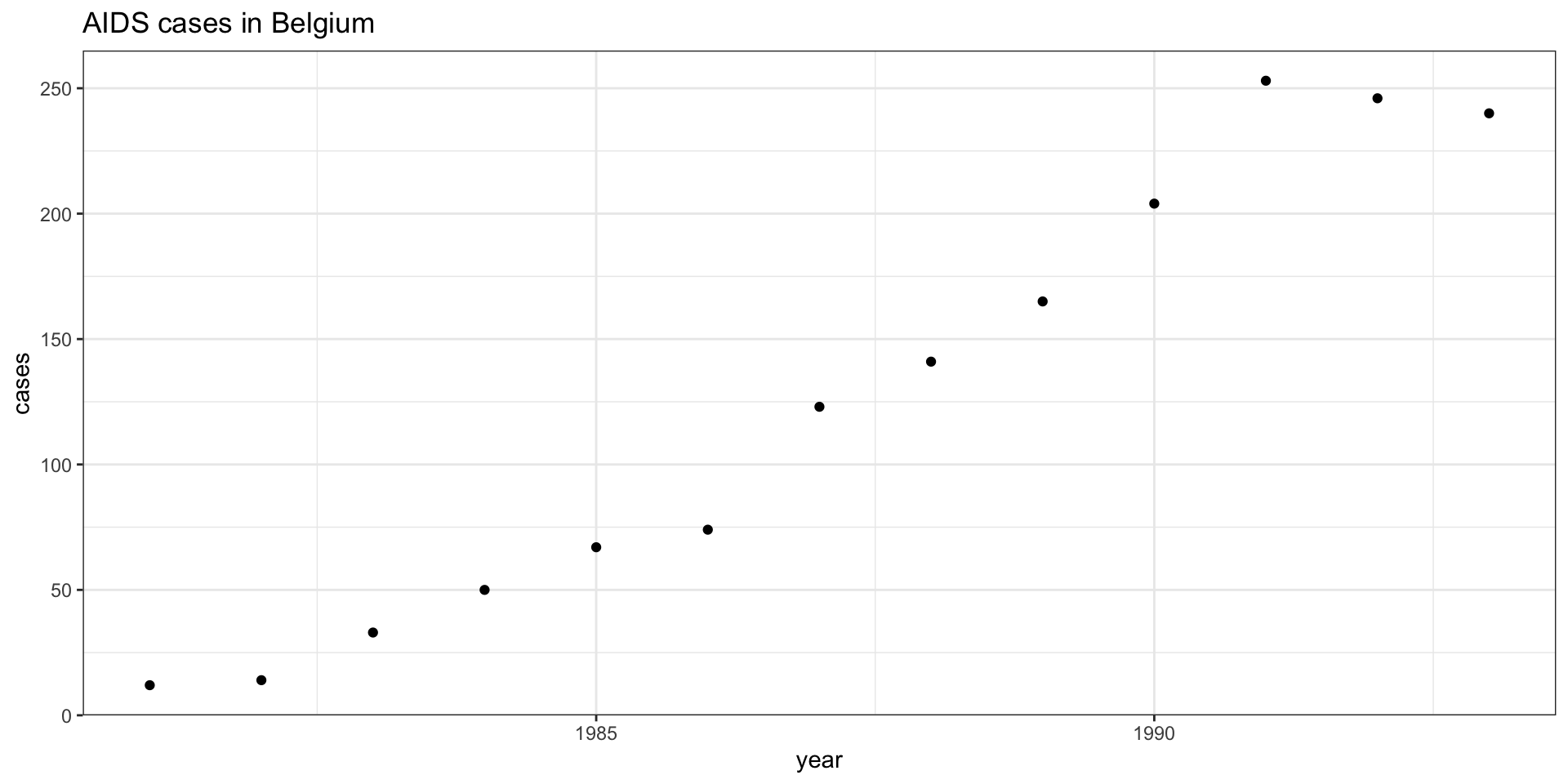
Model fit - \(Y\) CI
Residuals
Background
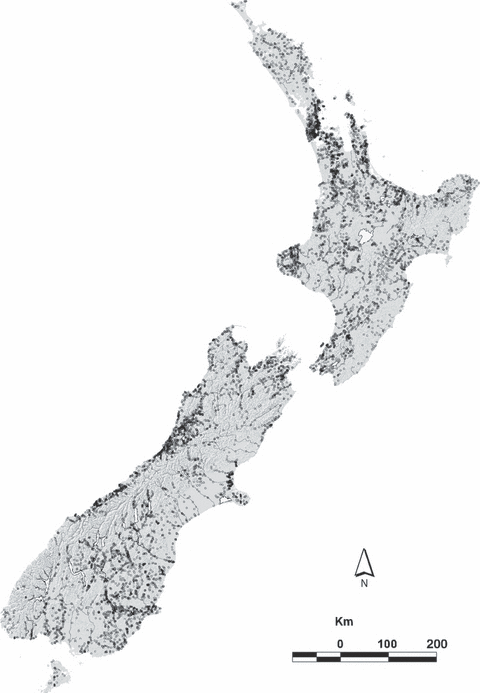
Next we’ll be looking at data on the presence and absence of the short-finned eel (Anguilla australis) at a number of sites in New Zealand.
These data come from
- Leathwick, J. R., Elith, J., Chadderton, W. L., Rowe, D. and Hastie, T. (2008), Dispersal, disturbance and the contrasting biogeographies of New Zealand’s diadromous and non-diadromous fish species. Journal of Biogeography, 35: 1481–1497.

Species Distribution
EDA
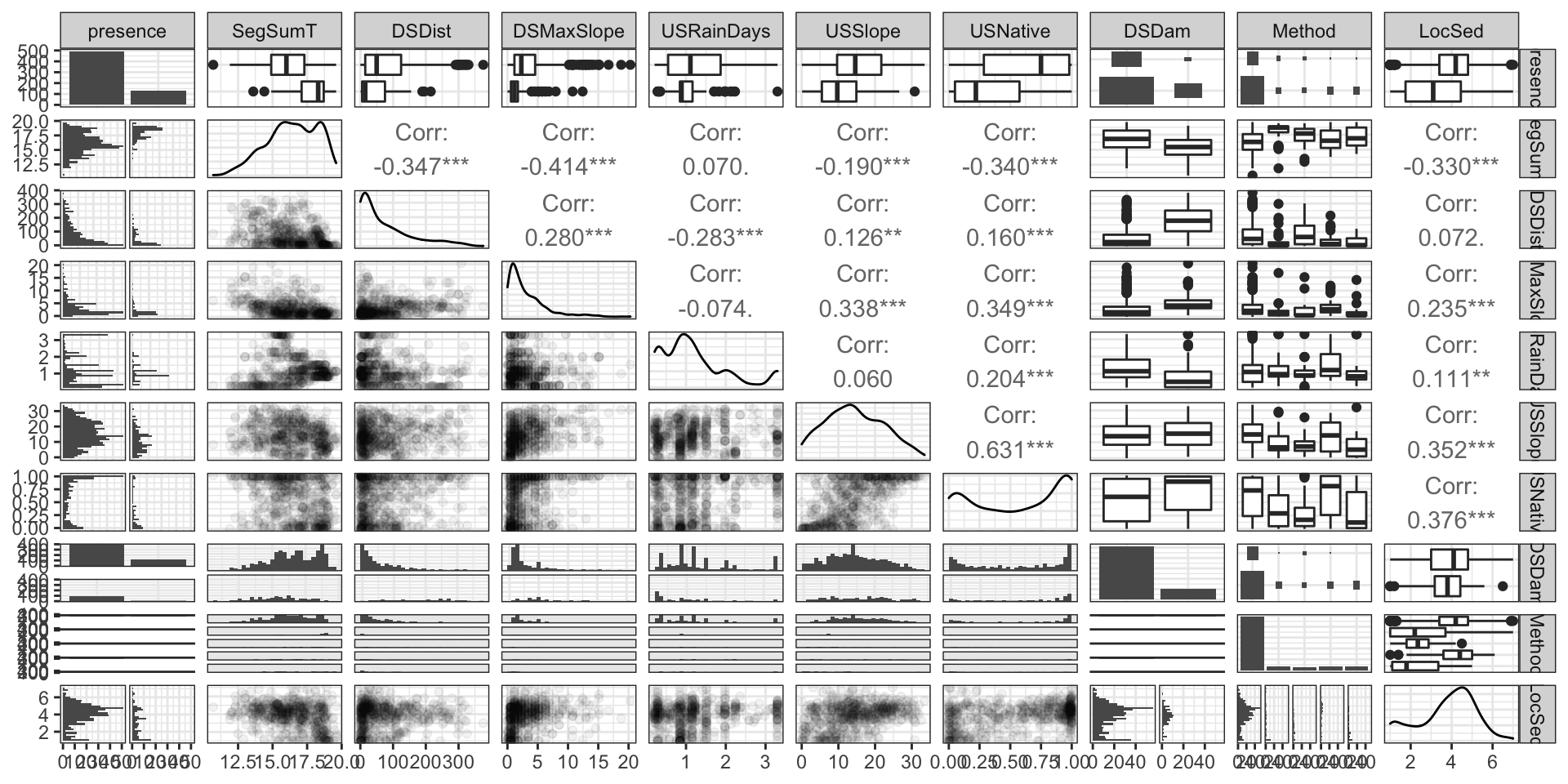
EDA (part 1)
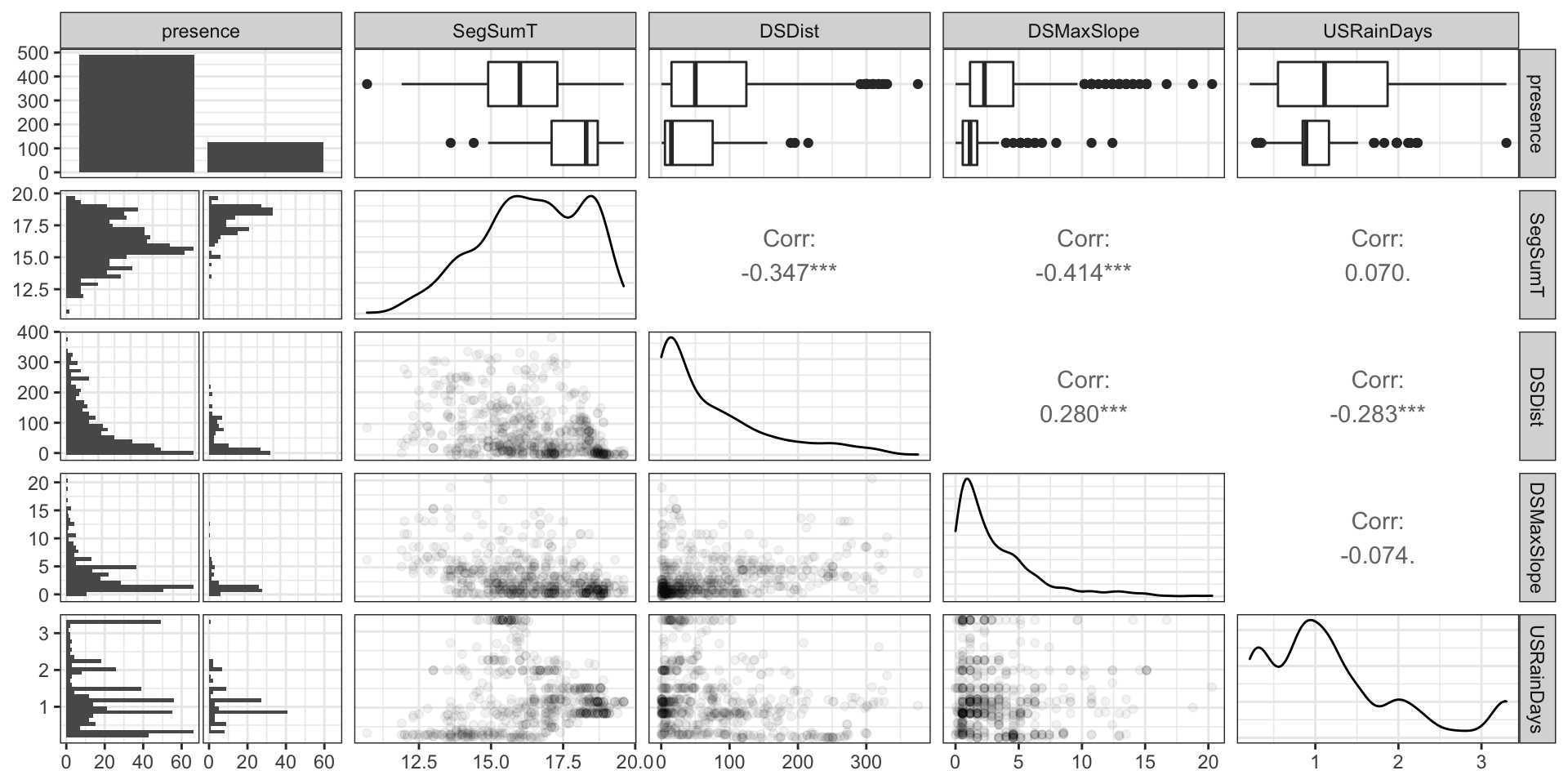
EDA (part 2)
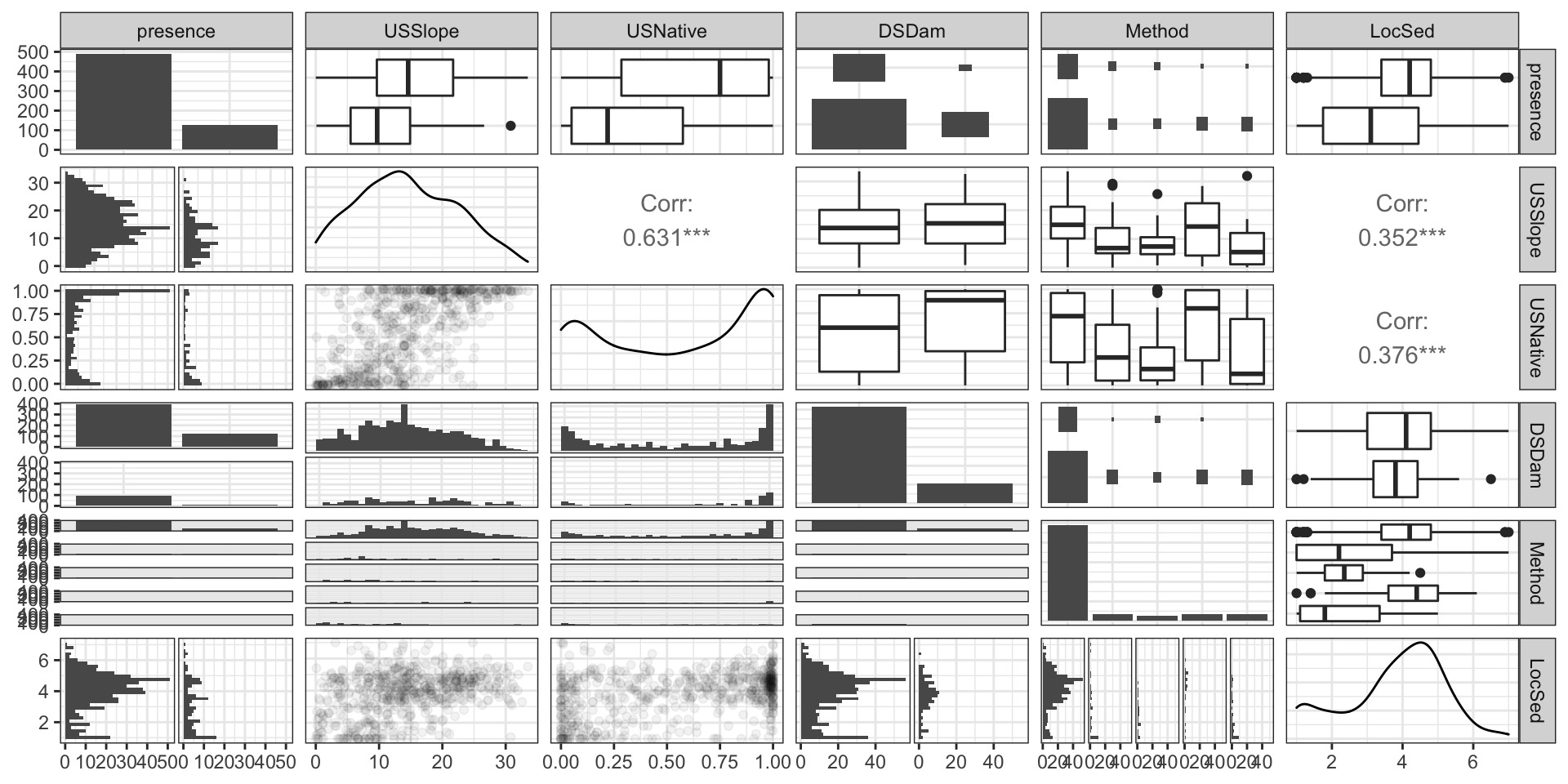
EDA (part 3)
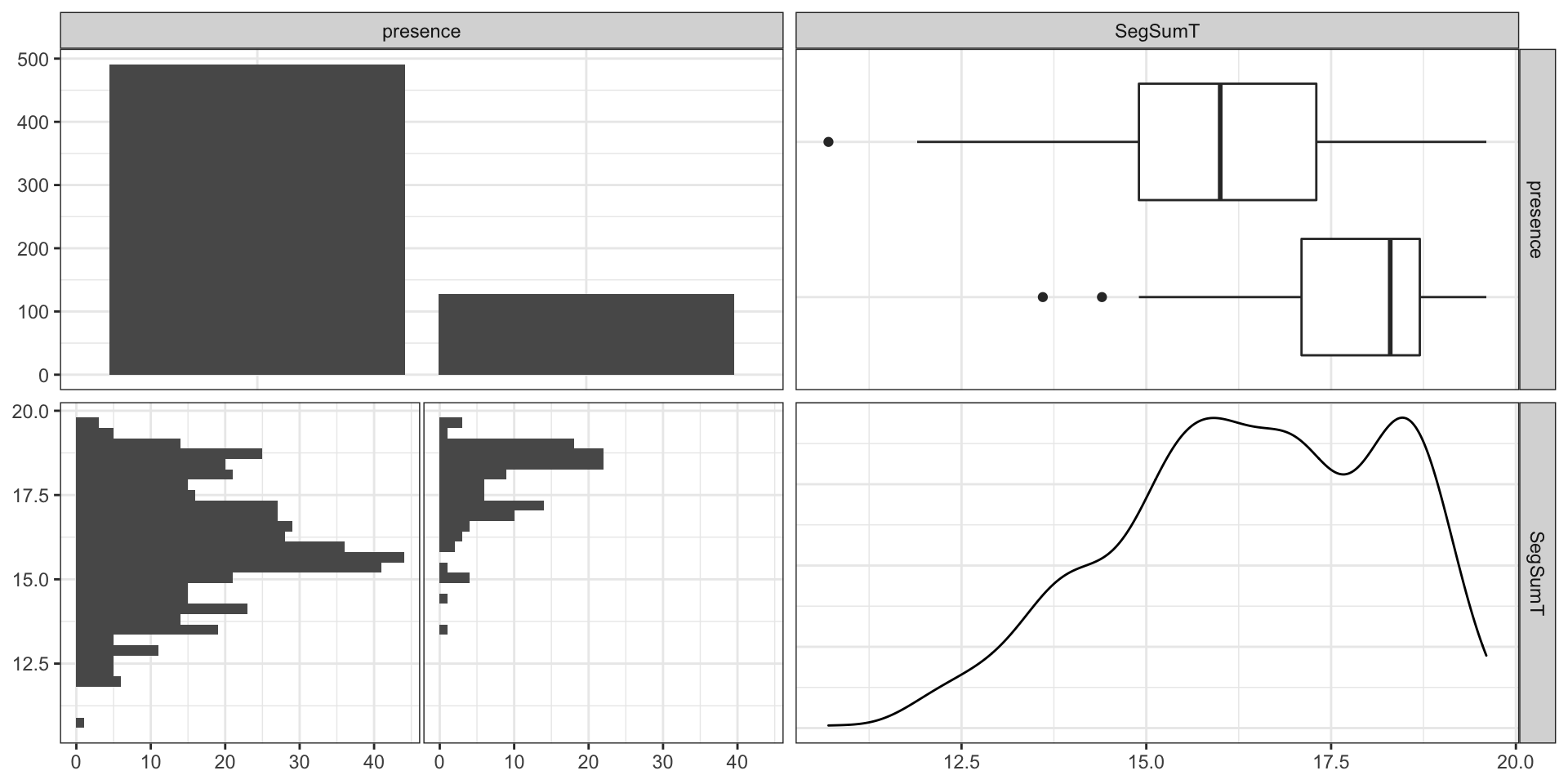
Visually
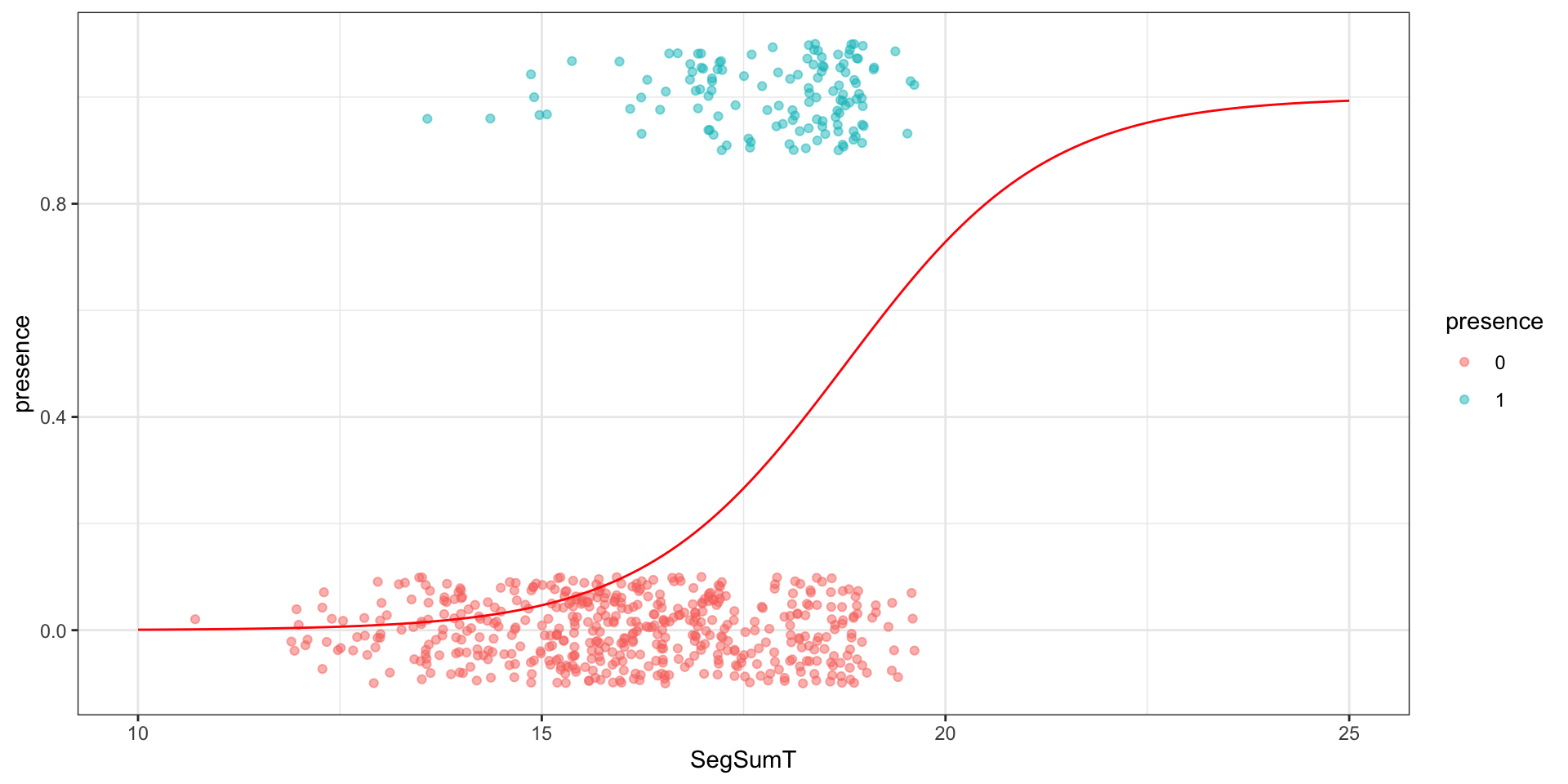
Separation
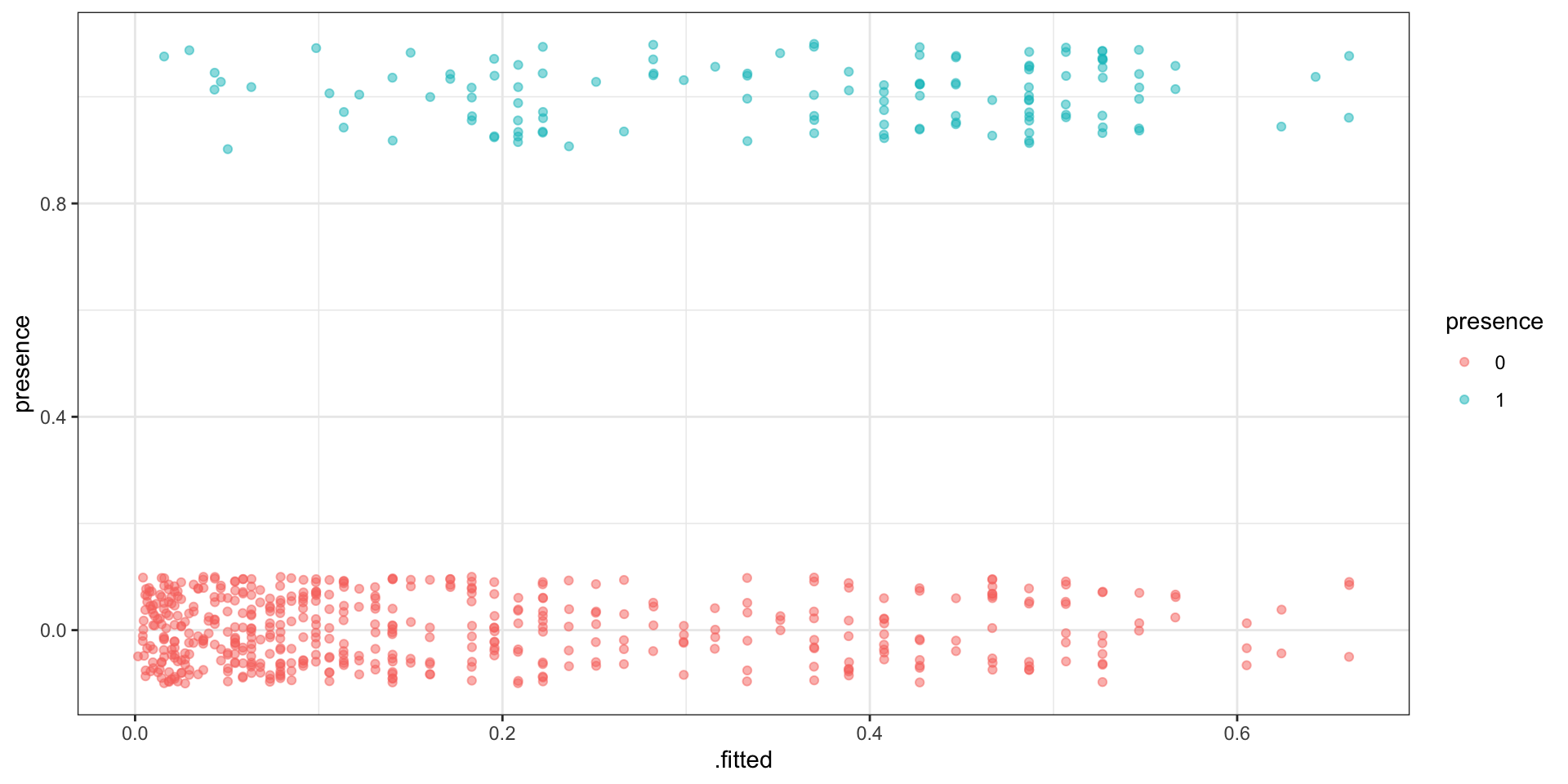
Standard Residuals
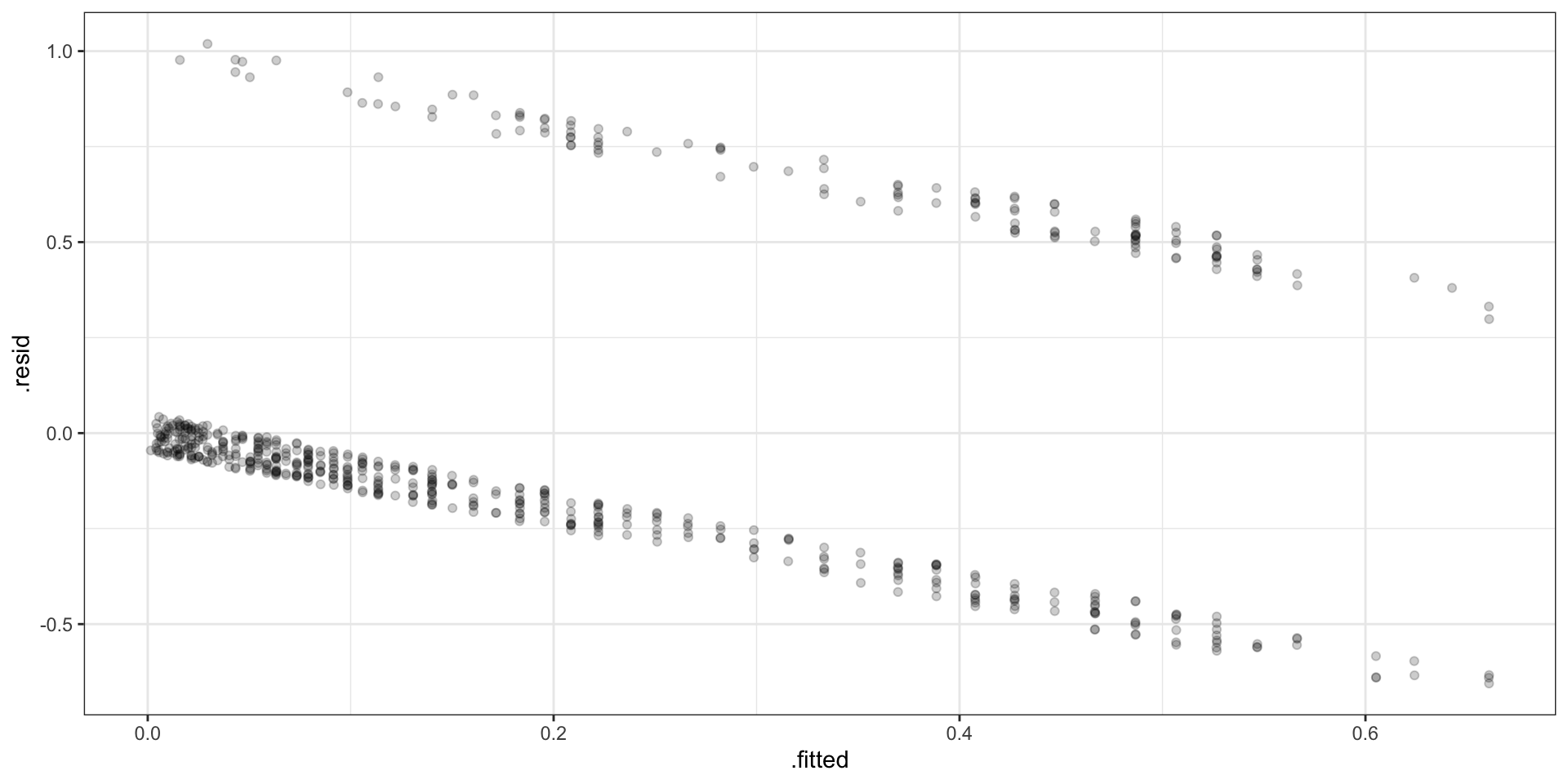
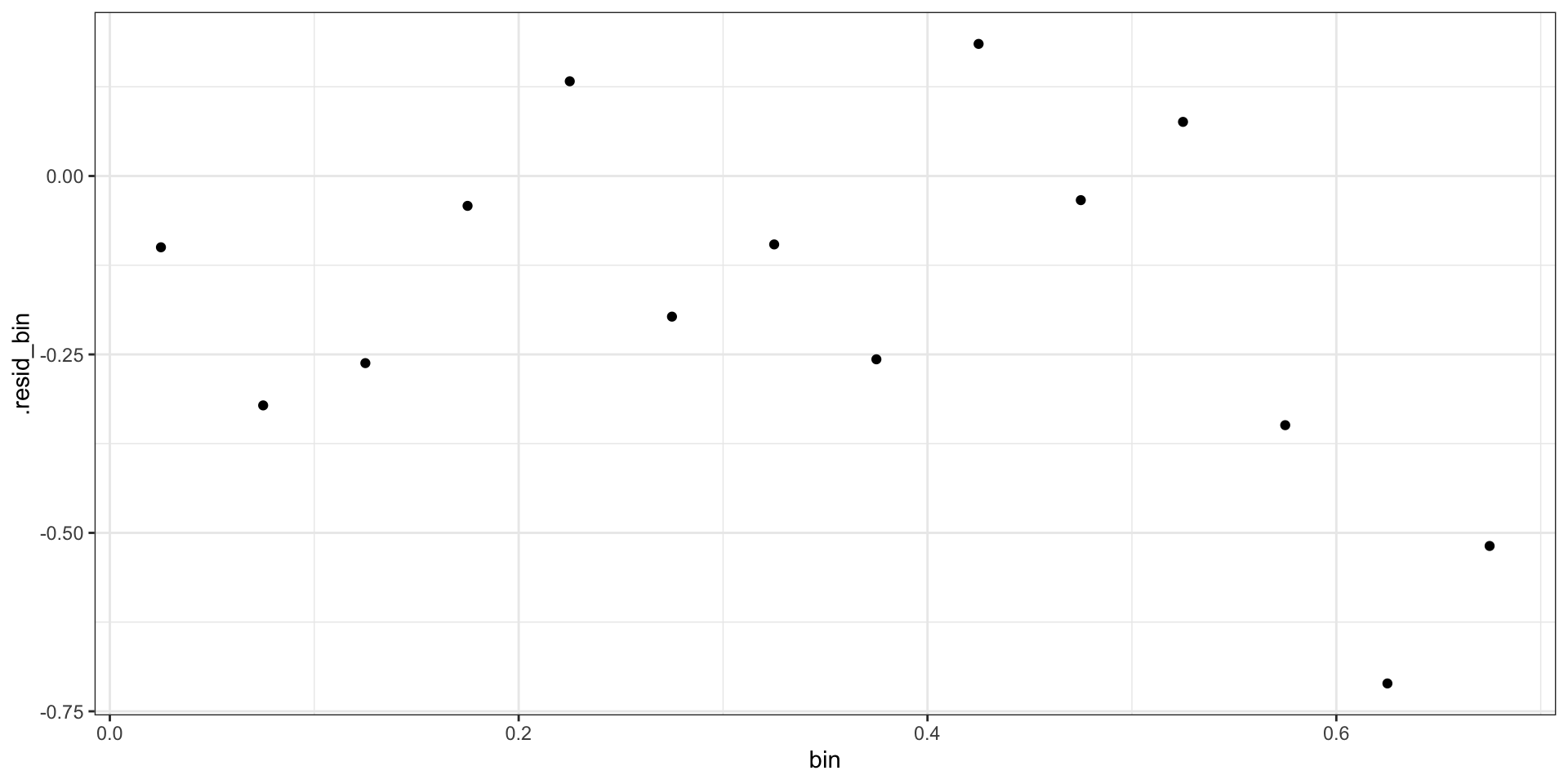
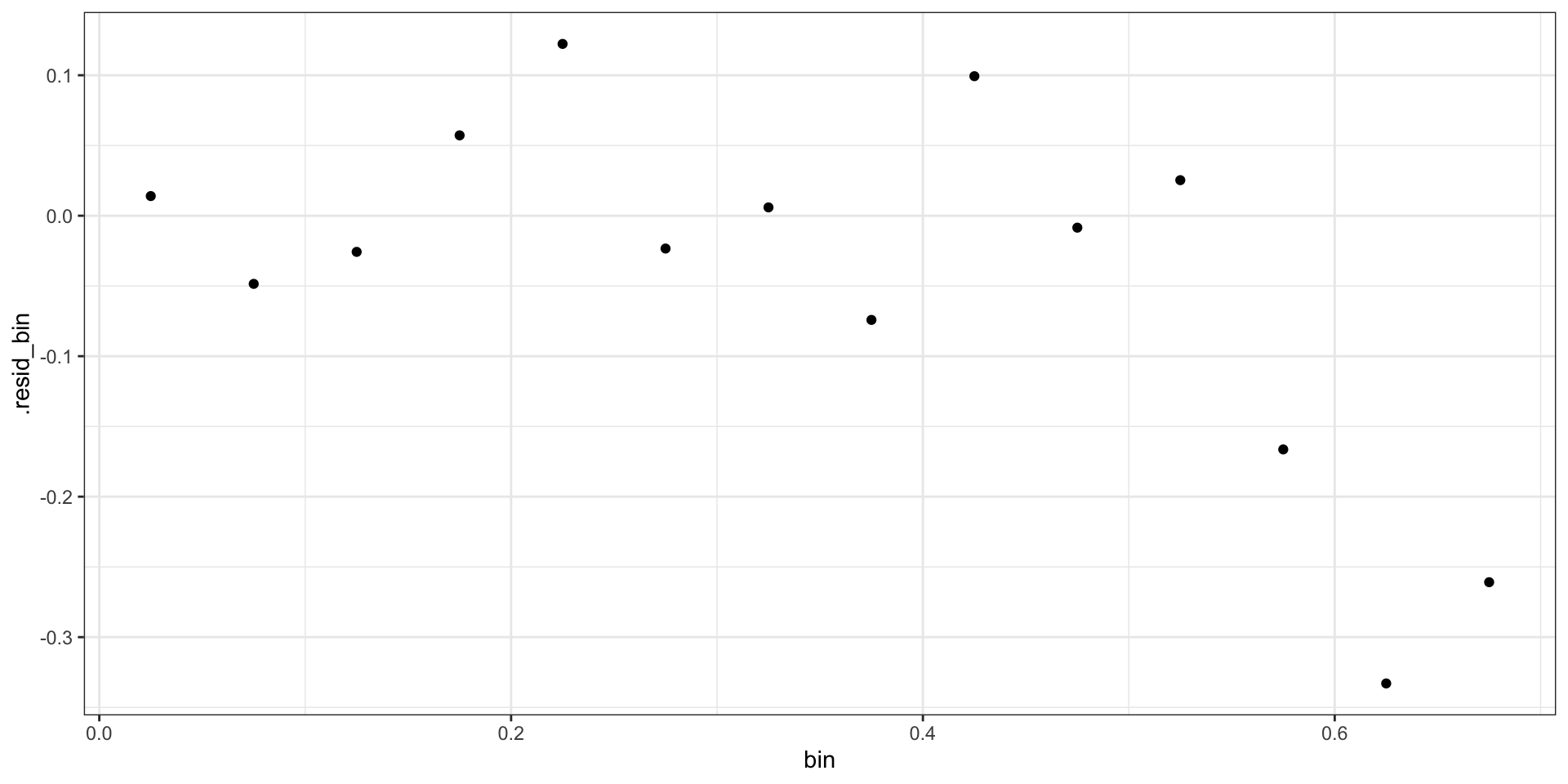
Binned Residuals
Pearson Residuals
\[ r_i = \frac{Y_i - E(Y_i)}{\sqrt{Var(Y_i)}} = \frac{Y_i - \hat{p}_i}{\sqrt{\hat{p}_i(1-\hat{p}_i)}} \]
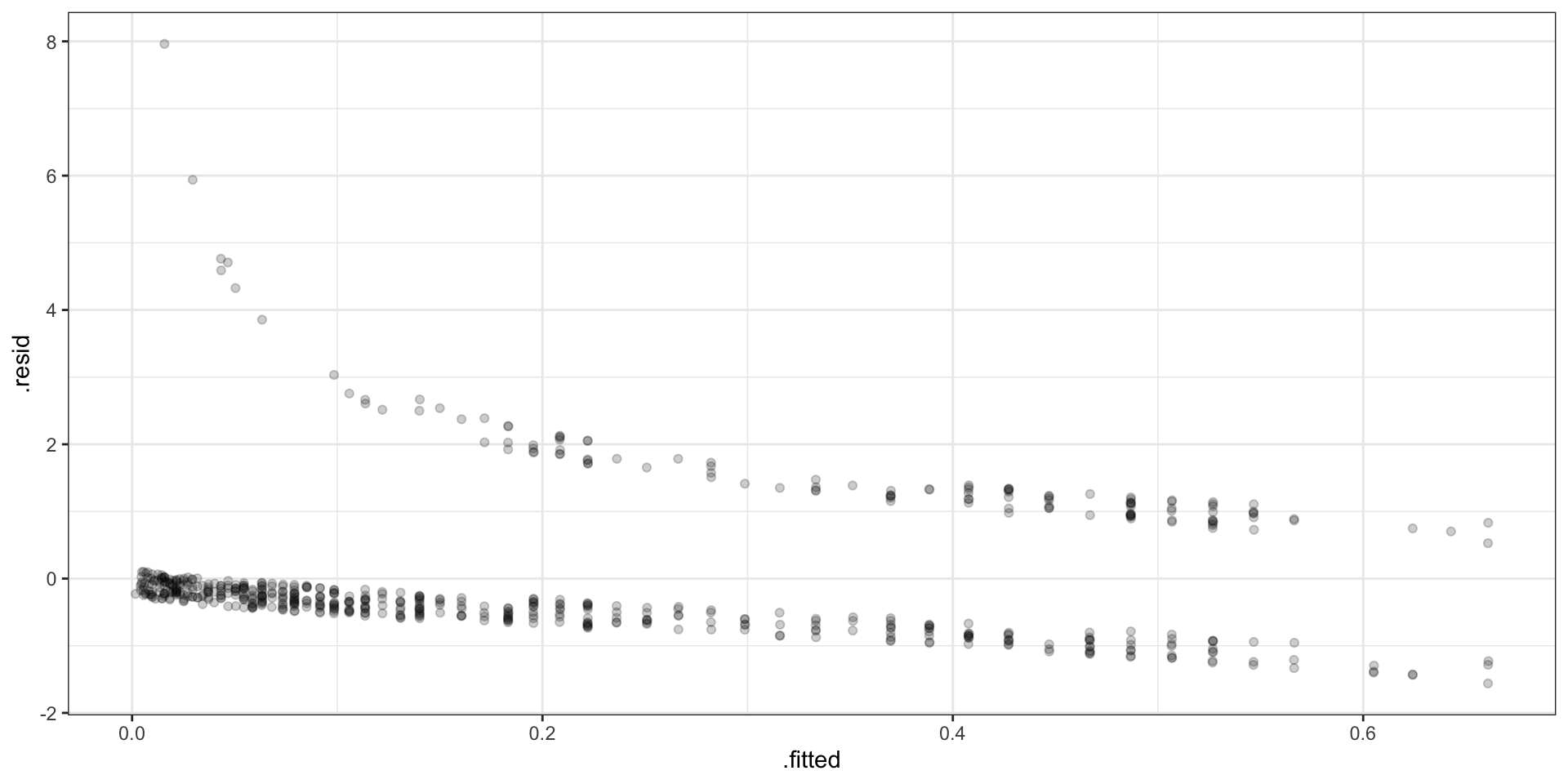
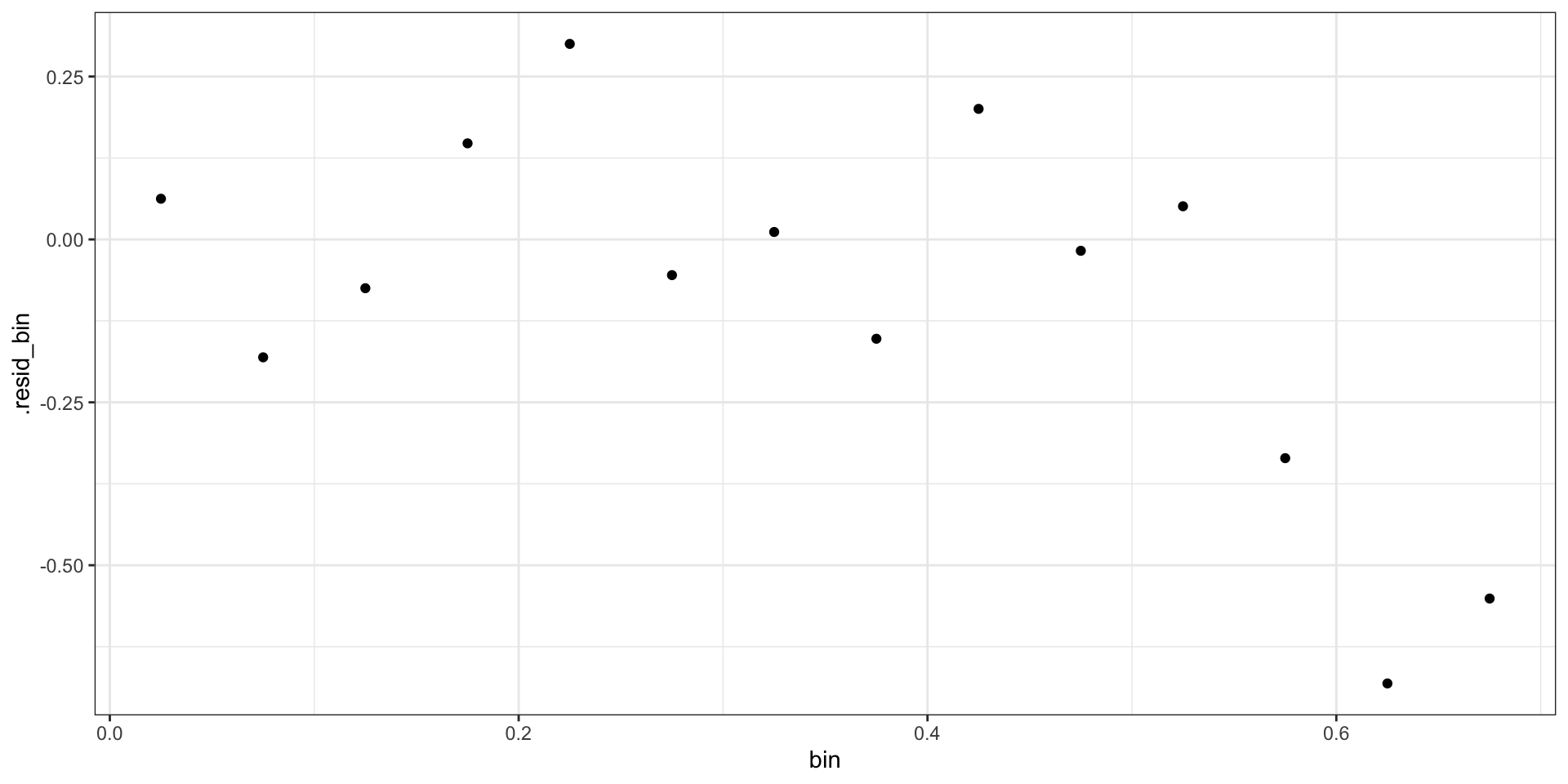
Binned Pearson Residuals
Deviance Residuals
\[ \begin{aligned} d_i = &\text{sign}(Y_i-\hat{p_i}) \, \times \\ &\sqrt{ -2 \left(Y_i \log \hat{p}_i+(1-Y_i)\log (1 - \hat{p}_i) \right) } \end{aligned} \]
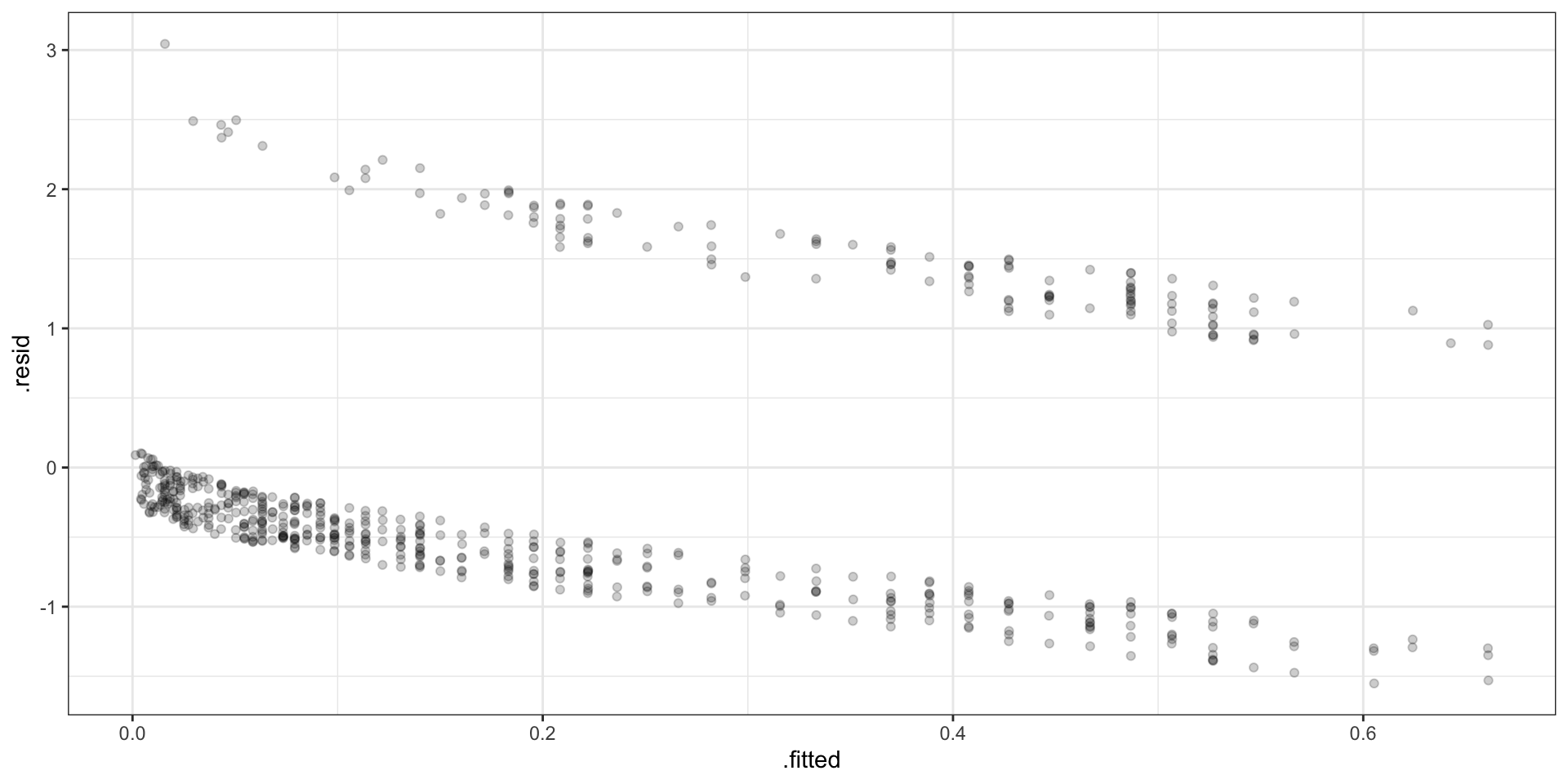
Binned Deviance Residuals